
Heterogeneous Federated Learning
下载链接
0x00 Abstract
为了解决数据分散的问题,提出了一种新的联邦学习框架,协作模型之间建立牢固的结构信息对齐方式。
设计一种特征定向提取的方法(Ψ−Net\varPsi-NetΨ−Net),该方法能确保在不同的网络中都有明确的特征信息。
KEY WORDS: Permutation invariance,FedAvg,Convergence
0x01 Introduction
FedAvg算法在高度Non-IID的情况下,性能损失会很严重。
不同节点的初始模型是相同的,但是在不同的本地数据训练的情况下,导致了参数的不同,这就是基于坐标平均的缺点。
已经有学者研究"Permutation invariance"等方式,但任然存在参数不精确匹配、额外计算、扩展性差等局限性。
为了解决上述限制问题,我们提出了自己基于结构和信息对齐的FL架构。下图展示对比FedAvg的优点:
0x02 Background and Motivation
Neural Network Permutation Invariance
F(X)= ...
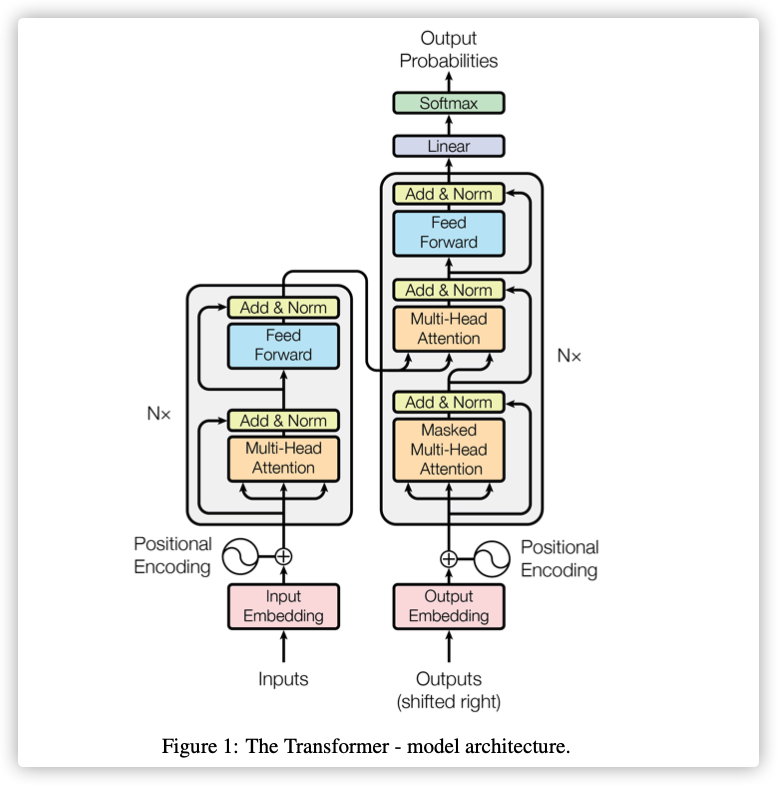
Attention is all you need
下载链接
博客参考
0x00 Abstract
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
KEY WORDS:Attention mechanism,Transformer,RNN,CNN
0x01 Introduction
RNN需要根据前一状态预测当前状态,这就导致了不能并行计算。
在大量实验中表示:Attention mechanism不需要考虑在输入或输出序列中的位置
本文提出Transformer模型,摒弃RNN,完全依赖A ...
Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
下载链接
0x00 Abstract
本文提出了Federated distillation(FD),一种分布式训练算法,通信开销比传统的模式少。为了解决数据非独立同分布的问题,本文提出了federated augmentation(FAug),每个设备协作训练一个生成模型,利用它进行数据集的扩充,使数据达到独立同分布。
KEY WORDS:Federated Distillation,FAug,GAN
0x01 Introduction
**问题:**Non-IID导致的准确度损失可以通过交换部分数据完成修复,但这就引入额外的通信开销和隐私泄露问题。
本文贡献:
FD:一种分布式知识蒸馏技术,payload大小与模型大小无关,而与输出维度大小相关。
FAug:利用GAN的生成器添加数据,达到IID的效果。(这是通信与隐私之间的trade-off)。
0x02 Federated distillation
传统的分布式学习每轮都要交换整个模型,FL为了降低通信开销,在本地训练多轮之后进行交换模型信息。则FD交换的是模型的输出,而不是模型本身,这使训练节点能够自定义本地模型大小。
...
FEDERATED LEARNING: STRATEGIES FOR IMPROVING COMMUNICATION EFFICIENCY
下载链接
0x00 Abstract
在本文中提出了两种减少上传开销的更新策略:structured updates 和 sketched updates。
structured updates:从限制的参数空间使用较少数量的变量来更新。
sketched updates:学习完整模型,利用量化、随机旋转、二次取样等方法进行压缩传输。
KEY WORDS:COMMUNICATION EFFICIENCY,uplink communication cost
0x01 Introduction
现状:
传统的聚合过程,每轮都需要发送完整的模型。
上传速度往往低于下载速度(体现模型压缩的需求)
现有的网络压缩模型能够降低下载的带宽占用,结合加密技术能好糊用户的隐私。
Hti=Wti−Wt,for i∈St.Wt+1=Wt+ηtHt, Ht:=1ntΣi∈StHti.H_t^i=W_t^i-W_t,for\ i \in S_t.\\
W_{t+1}=W_{t}+\eta _{t}H_t,\ \ H_t:=\frac{1}{n_t}\Sigma_{i \in S_t}H_t^ ...
Trust Region Policy Optimization
下载链接
不知道写什么了。。。。
0x00 Abstract
对理论方法进行近似,本文提出了一种新算法TRPO;TRPO的近似值可能偏离理论,但是能够在对超参调整很小的情况下,实现单调提升。
KEY WORDS:Reinforcement Learning,TRPO,On-Policy
0x01 Introduction
目前策略优化的方案大致分为三类:
Policy iteration methods:在估计当前策略的价值函数和更新策略之间交替进行
Policy gradient methods:从样本轨迹中预估价值
Derivative-free optimization methods:将成本视为黑匣子,进行优化,如交叉熵、协方差等方法
本文贡献:
证明最小化替身函数,能保证策略以不小的步长进行更新
对理论方法进行近似,得到一种实际算法TRPO
两种变体:
Single-path: model-free setting
Vine: particular states, only in simulation
0x02 Preliminaries
0x03 Monot ...
Proximal Policy Optimization Algorithms
下载链接
0x00 Abstract
传统的数据样本在策略更新后就会失效,本文提出了一种新的目标函数,能够有效利用数据样本、进行多轮更新。
PPO算法与TRPO相比,执行更简单、泛化更好、采样更随机。
KEY WORDS:Reinforcement Learning,PPO,On-Policy
0x01 Introduction
强化学习常见的方法仍有提升的空间:扩展性(大量模型&并行执行)、数据利用率、健壮性。
Q-Learing:不能解决连续性问题、vanilla 策略梯度数据利用率和健壮性较差;
TRPO:过于复杂、与部分结构不兼容,如噪声(dropout)、参数共享
本文贡献:
PPO算法只用一阶优化就可以达到TRPO的数据利用率和相关性能表现。
目标函数引入Clip函数(修剪函数),能够获得算法性能的下界。
与其他算法的实验比较显示,性能较好。
0x02 Background: Prolicy Optimization
Policy Gradient Methods
常见的估值函数:
g^=E^t[▽θlogπθ(at∣st)A^t]\hat{g}=\hat ...
Advances and Open Problems in Federated Learning
一篇超长综述,不过这应该是假期前讲的最后一部分了 (~ ̄▽ ̄)~
下载链接
0x00 Abstract
Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine le ...
Local SGD Converges Fast and Communicates Little
Question:
Q:为什么SGD降低方差,可以提高收敛速率?
A:方差反应了梯度的波动,因此方差越小,说明梯度越集中,收敛就越快。
下载链接
0x00 Abstract
受限于网络延迟和带宽限制,多节点的随机梯度下降很难实现收敛的线性加速;Local SGD可以实现,但是缺乏理论证明。
本文证明了Local SGD对凸优化问题的收敛速度,能达到SGD与节点数和批次大小的线性加速关系。通信轮数能减少到T1/2T^{1/2}T1/2(TTT表示总轮数)。Local SGD也可用于异步参数更新。
Local SGD能用于大型深度学习模型的训练。
KEY WORDS: Local SGD,Theoretical, Speedup
0x01 Introduction
SGD的组成:
其中gtg_tgt的期望就是函数fff对xtx_txt的求导(fff是损失函数)。
parallel SGD:
用多个节点梯度的平均值,代替gtg_tgt
每轮节点都要通信交换,通信成为瓶颈
Mini-batch parallel SGD:
增加计算-通信比
每次通信前,训练m ...
DON’T USE LARGE MINI-BATCHES, USE LOCAL SGD
下载链接
0x00 摘要
在相同效率和扩展性的情况下,提出Post-loacl SGD和Hierarchical Local SGD,能够提高泛化表现,优化系统资源。
KEY WORDS:Local SGD,Post-local SGD
0x01 介绍
为了有效利用系统资源,算法需要满足保证通信效率的同时启用并行化,且有良好的泛化性能。
Mini-batch SGD
Local SGD
其中H表示本地训练步长,两者关系如下:
Large batch SGD
根据标准的mini-batch SGD扩大训练节点的数量,会使用更大的批次,这就导致系统效率和模型泛化能力下降,更会影响准确率。
以下两个场景除外:
通信限制设定:同步时间开销大于梯度计算时,可以使用大批次。
大批次泛化性能差:坚持使用小批次,保持并行性,会导致批次小于最优值,导致训练时间增加。
Main Results
Contributions
第一次全面的实践证明局部SGD通信效率和泛化性能的trade-off。
提出了Post-local SGD训练模式,提高了设备的并行性;在大批次训练情况下保证 ...
The Paillier Cryptosystem
同态加密–Paillier加密
0x01 基础知识
选择两个长度相同的大素数p,qp,qp,q。计算N=pqN=pqN=pq,会有以下三个结论:
1.gcd(N,ϕ(N))=1gcd(N,\phi(N))=1gcd(N,ϕ(N))=1
2.选择a≥0a\geq0a≥0,则有(1+N)a=(1+aN)modN2(1+N)^a=(1+aN)modN^2(1+N)a=(1+aN)modN2
3.构造的同构函数f:ZN×ZN∗→ZN2∗f: \mathbb{Z}_N × \mathbb{Z}^{*}_N →\mathbb{Z}^{*}_{N^2}f:ZN×ZN∗→ZN2∗。其中f(a,b)=[(1+N)a⋅bN]modN2f(a,b)=[(1+N)^a\cdot b^N]modN^2f(a,b)=[(1+N)a⋅bN]modN2
0x02 命题证明
gcd(N,ϕ(N))=1gcd(N,\phi(N))=1gcd(N,ϕ(N))=1
思路:gcd(p,ϕ(N))=1,gcd(q,ϕ(N))=1gcd(p,\phi(N))=1,gcd(q,\phi(N))=1gcd(p,ϕ(N))= ...
