下载链接
0x00 Abstract
传统的数据样本在策略更新后就会失效,本文提出了一种新的目标函数,能够有效利用数据样本、进行多轮更新。
PPO算法与TRPO相比,执行更简单、泛化更好、采样更随机。
KEY WORDS:Reinforcement Learning,PPO,On-Policy
0x01 Introduction
强化学习常见的方法仍有提升的空间:扩展性(大量模型&并行执行)、数据利用率、健壮性。
- Q-Learing:不能解决连续性问题、vanilla 策略梯度数据利用率和健壮性较差;
- TRPO:过于复杂、与部分结构不兼容,如噪声(dropout)、参数共享
本文贡献:
- PPO算法只用一阶优化就可以达到TRPO的数据利用率和相关性能表现。
- 目标函数引入Clip函数(修剪函数),能够获得算法性能的下界。
- 与其他算法的实验比较显示,性能较好。
0x02 Background: Prolicy Optimization
Policy Gradient Methods
常见的估值函数:
g^=E^t[▽θlogπθ(at∣st)A^t]
其中At^为优势函数。为了获得上面的梯度,需要的对下面的函数进行求导:
LPG(θ)=E^t[logπθ(at∣st)A^t]
使用相同数据执行多步更新的时候,往往导致策略更新后效果变差。
Trust Region Methods
TRPO提出的目标函数(替身函数)是一个求最大值的目标函数,并有更新幅度的限制:
θmaximize E^t[πθold(at∣st)πθ(at∣st)A^t]subject to E^t[KL[πθold(⋅∣st),πθ(⋅∣st)]]≤δ
TRPO使用的是硬性限制而不是惩罚(目标函数添加处罚项),但使用共轭梯度算法是二阶优化算法。
0x03 Clipped Surrogate Objective
令rt(θ)=πθold(at∣st)πθ(at∣st),rt(θold)=1,则TRPO的替身目标函数就是:
LCPI(θ)=E^t[πθold(at∣st)πθ(at∣st)A^t]=E^t[rt(θ)A^t]
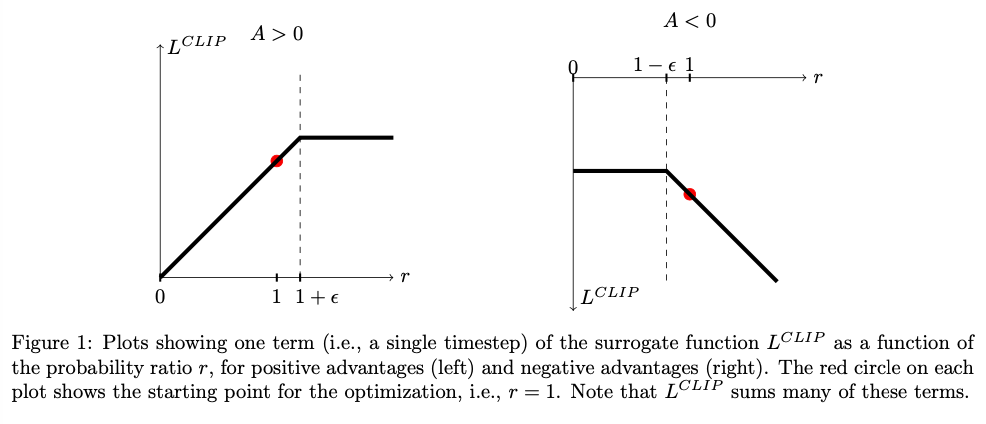
如果不对更新加以限制,会产生大幅度的消极更新,本文对该目标函数添加限制如下:
LCLIP(θ)=E^t[min(rt(θ)At^,clip(rt(θ),1−ϵ,1+ϵ)At^)
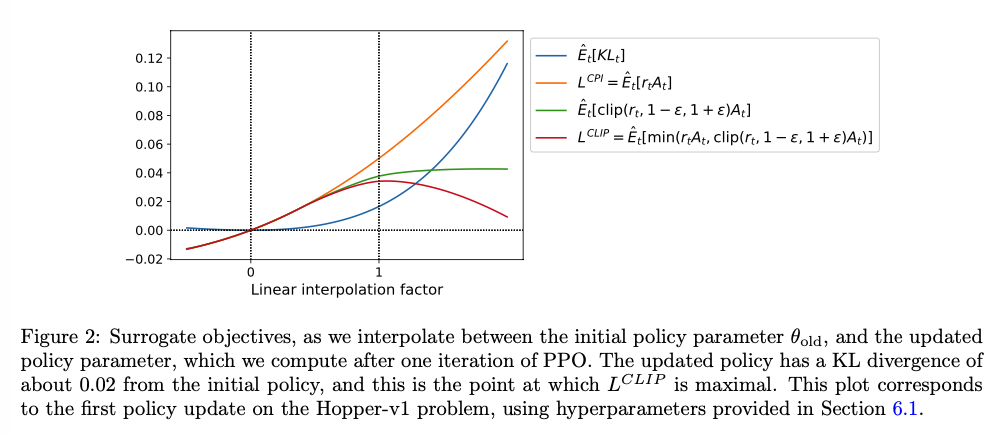
效果图如下:
0x04 Adaptive KL Penalty Coefficient
本节是用于凑字数的…
利用KL散度作为惩罚系数,但是效果不如CLIP好:

0x05 Algorithm
引入神经网路使用的目标函数:
LtCLIP+VF+S(θ)=E^t[LtCLIP(θ)−c1LtVF(θ)+c2S[πθ](st)]
其中c1,c2是系数,S是熵激励,LtVF=(Vθ(st)−Vttarg)2是二次误差。
前人工作者使用的TD-error型优势函数:
A^t=−V(st)+rt+γrt+1+...+γT−t+1rT−1+γT−tV(sT)
本文引入λ并修改优势函数如下:
A^t=δt+(γλ)δt+1+...+(γλ)T−t+1δT−1,where δt=rt+γV(st+1)−V(st)
N个(并行)actor中的每一个actor收集T个数据,进行训练:

0x06 Experiments
0x07 Conclusion
- 多轮随机梯度进行策略更新
- 与TRPO有相同的稳定性和可靠性,但执行更简单,应用范围更广
- 较好的综合性能
Note:
- First-order optimization
- conjugate gradient algorithm(共轭梯度法)
 wechat
wechat