Attention is all you need
0x00 Abstract
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
KEY WORDS:Attention mechanism,Transformer,RNN,CNN
0x01 Introduction
- RNN需要根据前一状态预测当前状态,这就导致了不能并行计算。
- 在大量实验中表示:
Attention mechanism不需要考虑在输入或输出序列中的位置 - 本文提出
Transformer模型,摒弃RNN,完全依赖Attention mechanism
0x02 Background
- 传统模型处理两个
Inputs的位置属性所添加的计算量与位置距离相关,距离越远,需要的计算量越大。 Self-attention在阅读理解、摘要总结、文字蕴含等领域取得了不错的表现- End-to-end memory networks are based on a recurrent attention mechanism instead of sequence- aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
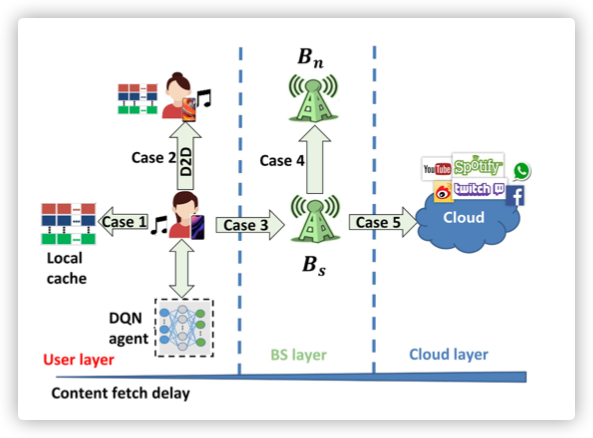
0x03 Model Architecture
整体结构如下:
1. Component
Encoder:实验设计的 N=6
Decoder:实验设计的 N=6
Add&Norm:为残差网络的正则化,LayerNorm(x+Sublayer(x))
向量维度 :
Masked和Multi-head:后续会提到
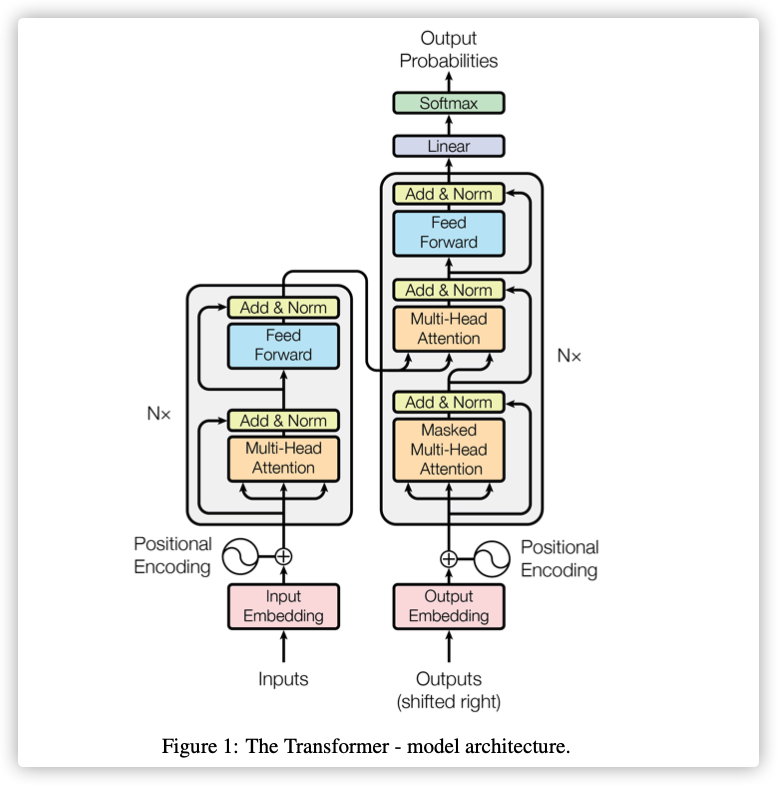
2.Attention
Attention的核心思想:
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.

K=Q 就是self-attention K!=Q 就是cross-attention
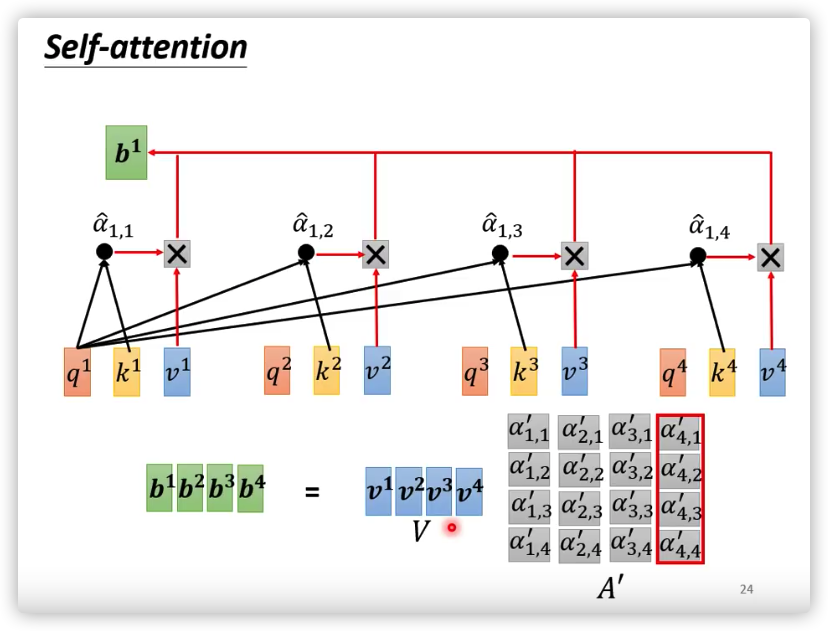
Scaled Dot-Product Attention
用和,计算相关性,作为的权重
-
计算相关性使用的是向量内积
-
缩放除以,是为了统一化,
的函数性质:过大或过小都会使其导数接近于0,不利于反向传播。
-
其中都是由 经过不同的线性变换获得:
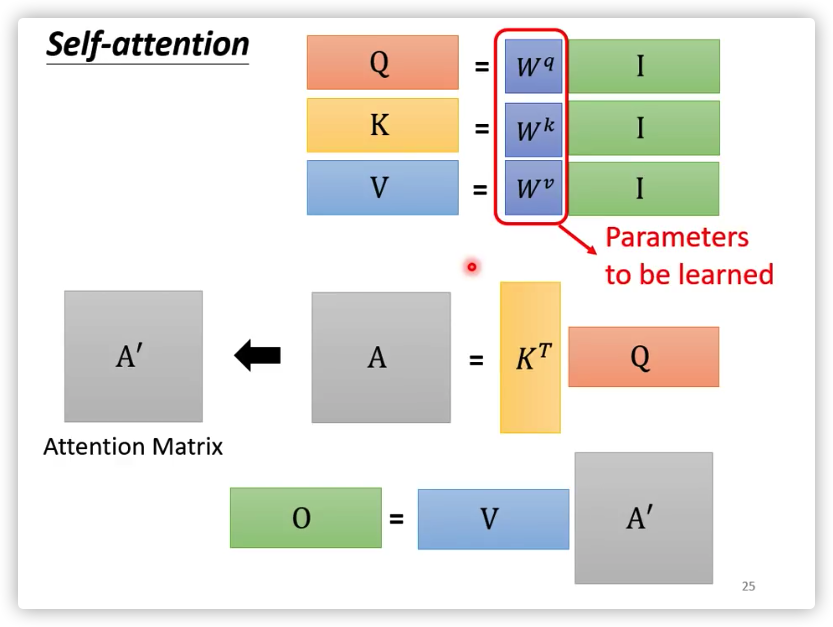
其中就是需要训练的参数!!!
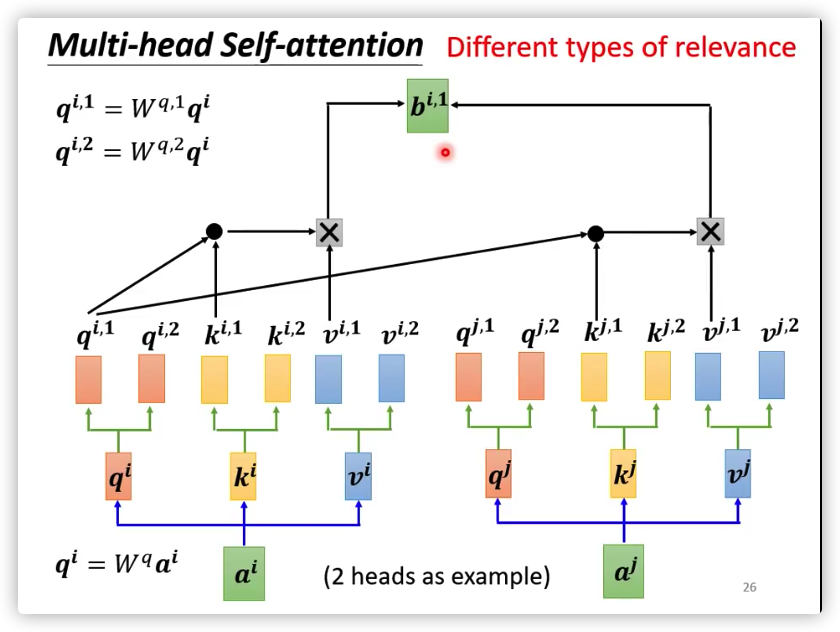
Multi-Head Attention
从多维度进行 Attention,获取更多的信息:
实验中设置.
这里的三个向量均乘以矩阵,是为了扩展出不同维度的
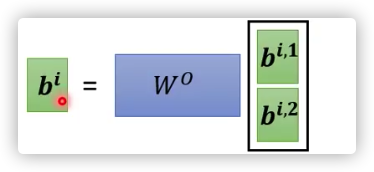
将不同维度的信息合并:
3.Position-wise Feed-Forward Networks
Feed Forward :
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is , and the inner-layer has dimensionality .
4.Embeddings and Softmax
Embeddings :将输入和输出转化成向量 vectors 计算,此处维度是
Softmax : 计算输出概率
In the embedding layers, we multiply those weights by .
Question:
目前还不清楚为啥这样操作?
5.Positional Encoding
-
模型少了卷积和循环结构,就少了输入向量之间的顺序关系。
盘算是个词语和算盘是个词语,在不考虑位置信息的情况下,这两句输入到Attention层的向量是相同,这显然不是我们所期望的。 -
为了利用输入的位置关系,就对位置进行编码。
-
将位置编码信息
positional encoding和内容编码信息input embedding相加,作为真正的输入。
0x04 Why Self-Attention
选择Self-Attention的原因:
One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies . Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.

0x05 Training
DataSet&Batching
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding, which has a shared source- target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary . Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
GPU
We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the bottom line of table 3), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
Optimizer
Adam:
learning rate:
Regularization
Residual Dropout We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of .
Label Smoothing During training, we employed label smoothing of value . This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
0x06 Results
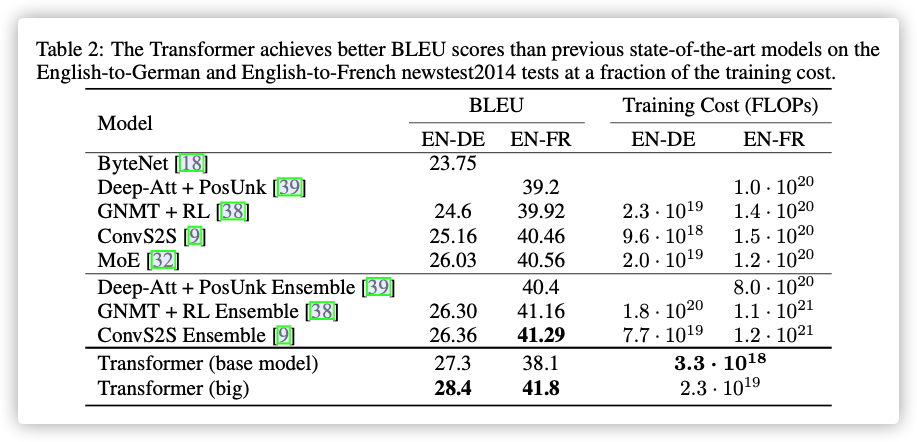
模型对比:
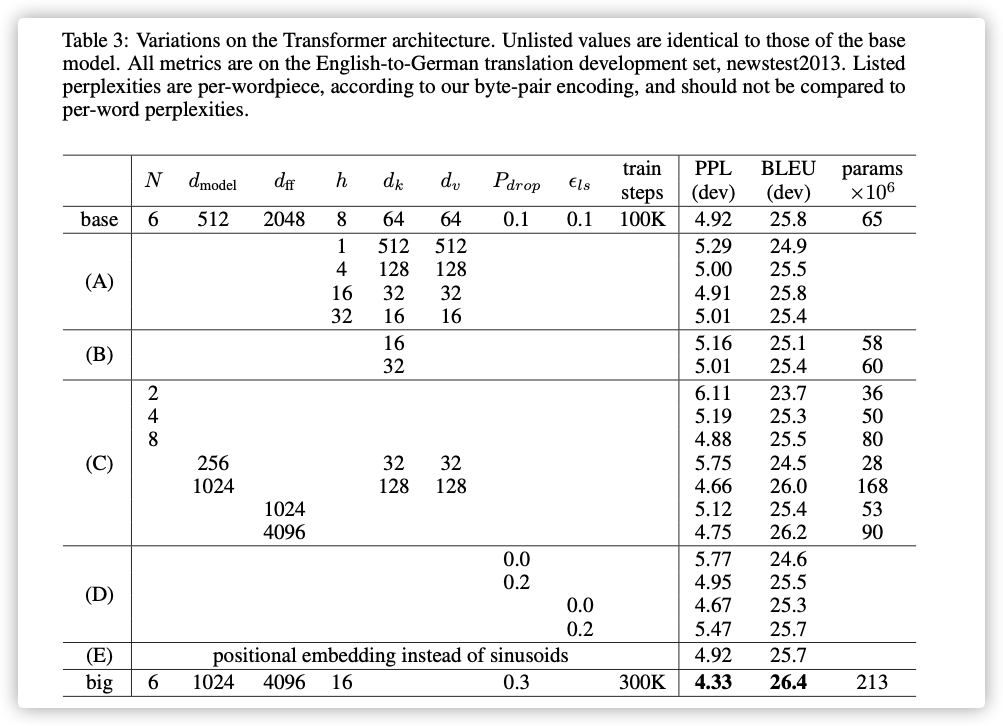
模型变体:
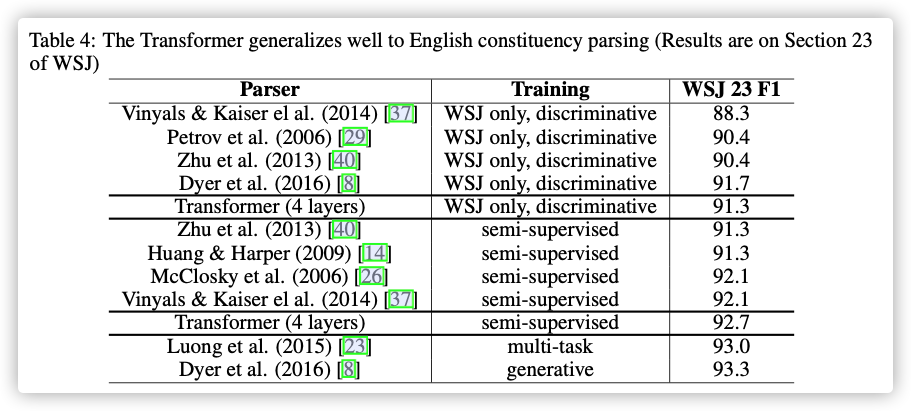
0x07 Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
参考:
 wechat
wechat