参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
0x07 值函数逼近
存在状态连续(或数目很多)的情况,这是存储表格已经不现实了。 注意:此时只是说状态数目多,未提及动作!
所以在想能不能设置一个函数,根据输入状态返回值?通过训练这个函数的参数,实现更新表的功能。
因此引入值函数逼近:
V(s)=V^(s,θ)Q(s,a)=Q^(s,a,θ)
逼近又分为线性逼近和非线性逼近:
1
2
3
4
5
6
7
8
9
| 函数逼近
|------线性逼近
| |---增量法逼近
| |---批量法逼近
|
|------非线性逼近
|---DQN
|---Double DQN
|---Dueling DQN
|
线性逼近
线性逼近就是将值函数表示为状态或者状态函数的线性组合,如:
V^(s,θ)=θTx(s)=i=1∑dθixi(s)
其中θ 为参数向量,x(s)为基函数,常见基函数有多项式基函数、傅里叶基函数。
增量法逼近
使学到的值函数尽可能的逼近真实的值函数,近似度常用最小二乘误差来度量:
Eθ=Eπ[(Vπ(s)−θTx(s))2]
采用梯度下降法,对误差求负导数:
−∂θ∂Eθ=Eπ[2(Vπ(s)−θTx(s))x(s)]
于是得到参数更新规则:
∇θ=α(Vπ(s)−θTx(s))x(s)
根据值函数计算的方式不同,又有以下几种情况:
-
基于蒙特卡罗方法的参数逼近:
∇θ=α(Gt−θTx(st))x(st)
-
基于时序差分法的参数逼近:
∇θ=α(Rt+1+γV^(St+1,θ)−V^(St,θ))∇θV^(St,θ)=α(Rt+1+γθTx(st)−θTx(st+1))x(st)
-
基于前向TD(λ)的参数逼近:
∇θ=α(Gtλ−V^(St,θ))∇θV^(St,θ)=α(Gtλ−θTx(st))x(st)
-
基于后向TD(λ)的参数逼近:
δt=Rt+1+γθTx(st+1)−θTx(st)Et=λγEt−1+∇θV^(St,θ)=λγEt−1+x(st)∇θ=aδtEt
但是有时需要对状态动作值函数进行逼近,则x(s)→x(s,a)
∇θ=α(Rt+1+γθTx(st+1,at+1)−θTx(st,at))x(st,at)
- 基于Q-Learning的参数逼近:
∇θ=α(Rt+1+γθTx(st+1,π(st+1))−θTx(st,at))x(st,at)
批量法逼近
增量法虽然简单但随机性较高,不能充分利用样本,因此引入批量法~
批量法是把一段时间内的数据集中起来,假设一定时间内的数据集为D={(s1,V1π),(s2,V2π)...(sT,VTπ)}。通过学习,进行函数拟合,满足损失函数L最小:
L(θ)=t=1∑T(Vtπ−θTx(st))2
对θ进行求导,使导数为0:
−∂θ∂L(θ)=2t=1∑T(Vtπ−θTx(st))x(st)=0
-
最小二乘蒙特卡罗方法参数为:
αt=1∑T(Gt−θTx(st))x(st)=0θ=(t=1∑Tx(st)x(st)T)−1t=1∑Tx(st)Gt
-
最小二乘时序差分方法:
αt=1∑T(Rt+1+γθTx(st+1)−θTx(st))x(st)=0θ=(t=1∑Tx(st)(x(st)−γx(st+1))T)−1t=1∑Tx(st)Rt+1
-
最小二乘前向TD(λ)方法:
αt=1∑T(Gtλ−θTx(st))x(st)=0θ=(t=1∑Tx(st)x(st)T)−1t=1∑Tx(st)Gtλ
-
最小二乘后向TD(λ)方法:
αδtEt=0θ=(t=1∑TEt(x(st)−γx(st+1))T)−1t=1∑TEtRt+1
-
最小二乘Sarsa方法(基于Q函数):
αt=1∑T(Rt+1+γθTx(st+1,at+1)−θTx(st,at))x(st,at)=0θ=(t=1∑Tx(st,at)(x(st,at)−γx(st+1,at+1))T)−1t=1∑Tx(st,at)Rt+1
-
最小二乘Q-learning方法(基于Q函数):
αt=1∑T(Rt+1+γθTx(st+1,π(st+1))−θTx(st,at))x(st,at)=0θ=(t=1∑Tx(st,at)(x(st,at)−γx(st+1,π(st+1))T)−1t=1∑Tx(st,at)Rt+1
非线性逼近
线性逼近
DQN方法
-
与Q-learning思想一致,可以理解成Q-Learning的深度学习版
-
使用深度神经网络提取特征,近似行为值函数(Q函数)
-
利用经验回放进行训练
-
设置两套网络:TD目标网络、动作值函数逼近网络
使用梯度更新方式如下:
θt+1=θt+α(r+γmaxa′Q(s′,a;θt)−Q(s,a;θt))∇Q(s,a;θt)
这样就导致行为值Q与目标值用得是同一个网络,这样就存在很大的关联性。因此引入一个目标网络,目标值网络需要由动作值函数网络周期性更新:
θt+1=θt+α(r+γmaxa′Q(s′,a′;θt−)−Q(s,a;θt))∇Q(s,a;θt)

PS:此时可以理解成,对参数的更新就是对网络的更新!
Target网络的更新方式:
- 直接赋值:θ−=θ
- 逐渐更新:θ−=(1−τ)θ−+τθ
Double DQN方法
研究学者发现,DQN和Q-Learning都会过高估计Q值,存在过优化的问题!以DQN为例:
a∗=argmaxaQ(st+1,a;θt−)YtDQN=Rt+1+γmaxaQ(st+1,a;θt−)
在DQN的过程中,存在选择行为和评估行为是同一个网络,以及同一个值函数~
Double DQN(DDQN) 分别采用不同的值函数来实现动作选择和评估:
YtDDQN=Rt+1+γQ(st+1,argmaxaQ(st+1,a;θt);θt−)
Dueling DQN方法
有些时候,影响下一状态的不仅仅是所选动作,还可能是当前状态!
比如单车已经非常倾斜了、不管怎么调整,下一秒都会倒下,此时当前状态对下一状态的影响更大!
因此提出将Q值分解为价值(Value)和优势(Advantage):
Q(s,a)=V(s)+A(s,a)
通俗理解,V(s)可以理解为该状态s下所有动作值函数乘以该动作的概率之和,即动作值函数关于动作概率的期望。所以Q(s,a)−V(s)就表示当前动作对于其他动作的优势。
-
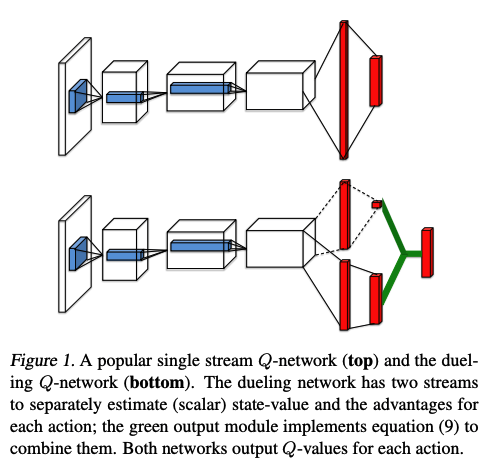
Dueling DQN的思路:
把Q网络(求取Q值的神经网络)的结构显式地约束成两部分之和:更动作无关的状态值函数V(s),与在该状态下各个动作的优势函数A(s,a)。
-
Dueling DQN结构图:
-
网络参数,θ为卷积网络参数,α,β分别为全连接层网络参数:
Q(s,a;θ,α,β)=V(s;θ,β)+A(s,a;θ,α)
-
New Problem:
上述等式中,存在两个未知数,这样就会出现一个无法识别的问题:给定一个Q,无法得到唯一的V和A (比如V和A同时加/减 相同的量),于是就有如下改进:
Q(s,a;θ,α,β)=V(s;θ,β)+(A(s,a;θ,α)−maxa′A(s,a′;θ,α))
上述等式就能唯一确定V和A,但是实际使用中,更倾向于下面的等式:
Q(s,a;θ,α,β)=V(s;θ,β)+(A(s,a;θ,α)−∣A∣1a′∑A(s,a′;θ,α))
这样缩小了Q的范围,去除多余的自由度,提高算法的稳定性!
 wechat
wechat