Communication-Efficient On-Device Machine Learning: Federated Distillation and Augmentation under Non-IID Private Data
0x00 Abstract
本文提出了Federated distillation(FD),一种分布式训练算法,通信开销比传统的模式少。为了解决数据非独立同分布的问题,本文提出了federated augmentation(FAug),每个设备协作训练一个生成模型,利用它进行数据集的扩充,使数据达到独立同分布。
KEY WORDS:Federated Distillation,FAug,GAN
0x01 Introduction
**问题:**Non-IID导致的准确度损失可以通过交换部分数据完成修复,但这就引入额外的通信开销和隐私泄露问题。
本文贡献:
- FD:一种分布式知识蒸馏技术,payload大小与模型大小无关,而与输出维度大小相关。
- FAug:利用GAN的生成器添加数据,达到IID的效果。(这是通信与隐私之间的trade-off)。
0x02 Federated distillation
传统的分布式学习每轮都要交换整个模型,FL为了降低通信开销,在本地训练多轮之后进行交换模型信息。则FD交换的是模型的输出,而不是模型本身,这使训练节点能够自定义本地模型大小。
Co-distillation(CD):
In CD, each device treats itself as a student, and sees the mean model output of all the other devices as its teacher’s output.
The teacher-student output difference is periodically measured using cross entropy that becomes the student’s loss regularizer, referred to as a distillation regularizer, thereby obtaining the knowledge of the other devices during the distributed training process.
CD is however far from being communication-efficient. The reason is that each logit vector is associated with its input training data sample. Therefore, to operate knowledge distillation, both teacher and student outputs should be evaluated using an identical training data sample. This does not allow periodic model output exchanges. Instead, it requires exchanging either model outputs as many as the training dataset size, or model parameters so that the reproduced teacher model can locally generate outputs synchronously with the student model.
过程如下:
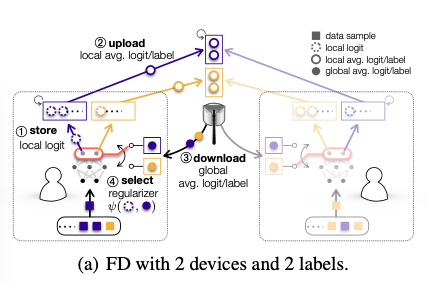
为了解决CD的问题,FD中的每个设备都会存储每个标签的均值向量,并且周期性的向服务器传输本地平均对数向量(local-average logit vectors)。服务器会将收集的向量按照标签再次进行平均,获得全局平均对数向量(global-average logit vector)。设备将其下载到本地,作为teacher‘s output结合本地数据训练蒸馏正则器。
算法如下:

0x03 Federated augmentation
过程如下:
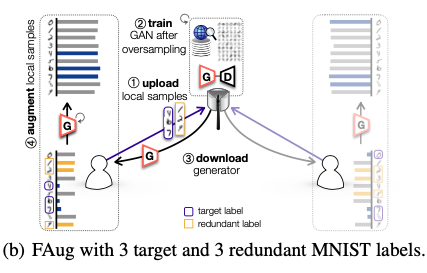
The generative model:
训练地点:服务器
过程:
- FAug中的每个设备检测到缺少标签(目标标签)后的数据,会将部分目标样本的种子上传至服务器;
- 服务器为了训练条件GAN,会对上传的种子进行过采样;
- 每个设备下载生成器,用于补充目标标签的数据样本,直到IID数据集。
- (为了保护数据隐私,会上传冗余标签)
Q:
FAug上传的数据数据比较个性化的部分,特征隐私不能用于FAug。私以为上述过程的保护作用不强( ̄▽ ̄)"
Privacy Leakage(PL):
- Device-Server PL:
- Level:
- Note:主要关注目标标签和冗余标签的数量关系
- Inter-Device PL:
- Level:
- Note:数量很大时可以忽略
0x04 Evaluation
数据集:MNIST
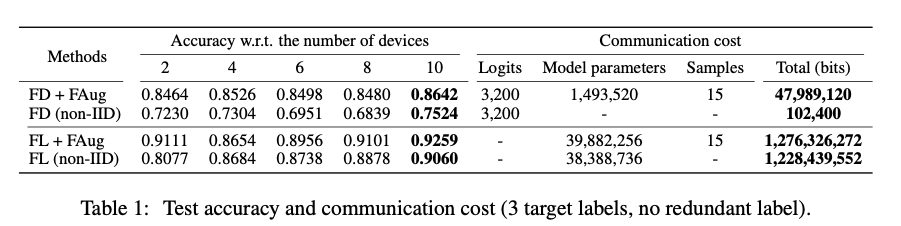
通信效果如下:
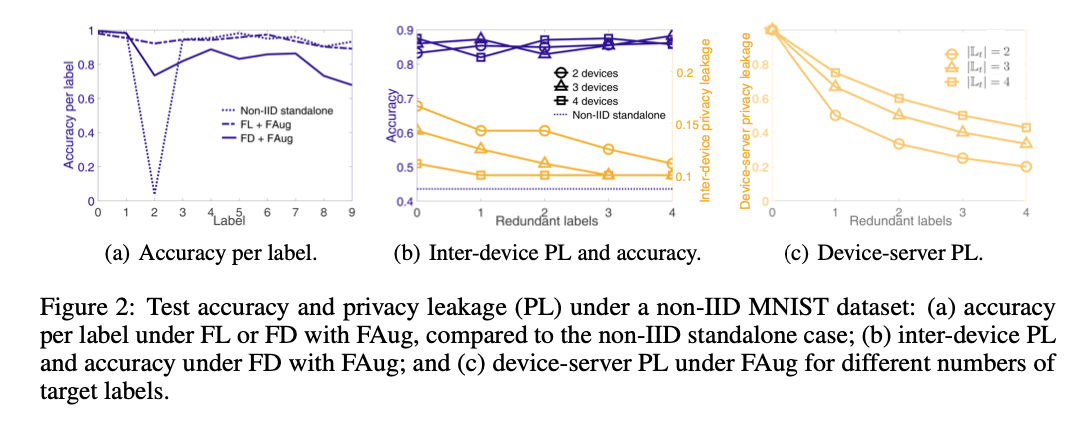
隐私问题:
0x05 Concluding remarks
Note:
- Conditional GAN
 wechat
wechat