参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
0x01 基础概念
什么是强化学习?
-
学习&规划
前者是指智能体未知环境模型,需要不断与环境进行交互,不断改进策略
后者是指已知大部分环境模型,智能体不再与环境进行交互,根据状态转移概率和回报,不断进改进策略
-
探索&利用:
探索未曾尝试的决策,主要体现在强化学习算法中的随机策略。
利用已收集的知识,主要体现在一些算法的贪心策略。
-
预测和控制
又叫评估与改善。
分别对应强化学习的打分阶段和策略改善阶段。
0x02 马尔可夫决策
马尔可夫性:下一时间步的状态s′,仅与当前时间步的状态s和所选动作a相关,与之前的状态、动作无关。
马尔可夫决策五元组:<S,A,R,P,γ>
贝尔曼方程:
状态值函数的数学表示如下,其中Gt是指到结尾的累计收益:
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+...∣St=s]
对其进行公式推导:
Vπ(s)=====Eπ[Gt∣St=s]Eπ[Rt+1+γRt+2+γ2Rt+3+...∣St=s]Eπ[Rt+1+γ(Rt+2+γRt+3...)∣St=s]Eπ[Rt+1+γGt+1∣St=s]Eπ[Rt+1+γVπ(St+1)∣St=s]
同理:
Qπ(s,a)==Eπ[Gt∣St=s,At=a]Eπ[Rt+1+γQπ(St+1,At+1)∣St=s,At=a]
以上是贝尔曼方程的最初形态,又因为状态值函数与行为值函数之间的关系:
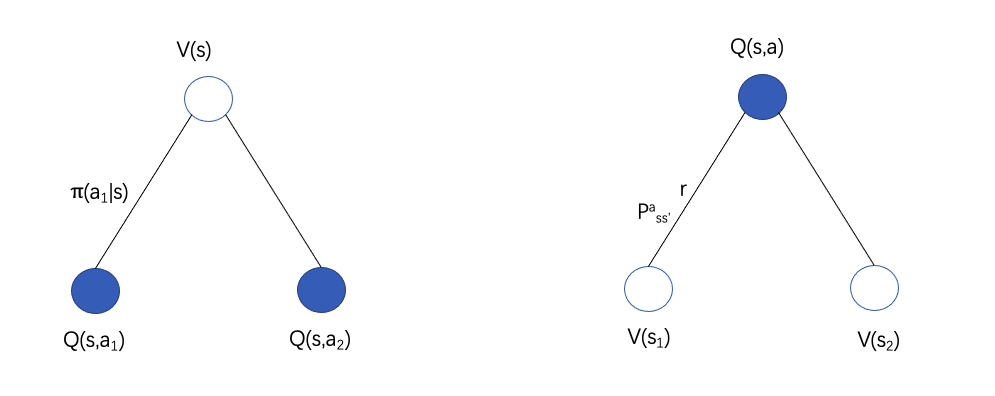
则又有以下形式:
Vπ(s)=a∈A∑π(a∣s)Qπ(s,a)
Qπ(s,a)=Rsa+γs′∈S∑Pss′aVπ(s′)
Vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′aVπ(s′))
Qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈A∑π(a′∣s′)Qπ(s′,a′)
0x03 动态规划
此部分不是重点
属于规划的范畴,即模型状态转移概率P是已知的,
0x04 蒙特卡罗 MC
未知模型,即转移概率P未知
核心思想:在问题领域进行随机抽样,通过不断、反复、大量的抽样后,统计结果,得到解空间上关于问题领域的接近真实的分布。
执行T步的一条完整轨迹如下:
<s0,a0,r0,s1,a1,r1,...sT,aT,rT>
为了计算方便,使用累计回报Gnt代替立即回报,n表示第n个轨迹:
<s0,a0,G11,s1,a1,G12,...sT,aT,G1T>
估算每个状态的状态值V(s)时有两种方式(处理一条轨迹中出现多次的相同状态的情况,即转圈情况):
- 初次访问:相同状态的累计回报只计算第一次
- 每次访问:每次经过都计算
V(s)=N(s)G12+G2k+...
其中N(s)表示所有轨迹中s出现的总次数,两者的区别就是分子是否有重复场景的情况。
MC的主要形式:估计行为值函数Q代替估计值函数V
Q(s1,a1)=N(s1,a1)G12+...
其中N(s,a)表示所有轨迹中状态行为对(s,a)出现的总次数,再结合增量更新方法:
Q(st,at)←Q(st,at)+α(Gt−Q(st,at))
0x05 时序差分 TD
MC计算的时候需要累积回报均值Gt,这就需要知道完整的轨迹(到终止状态)
但是存在未知完整轨迹或无终止状态的情况,因此引入时序差分。
因此实际情况中,主要使用TD值函数更新方式。
主要思想:在估计状态St的值函数时,用的是离开该状态的立即回报Rt+1和下一状态St+1的预估折扣值γV(St+1)之和,即:
Vπ(St)=Eπ[Gt∣St=s]=Eπ[Rt+1+γV(St+1)∣St=s]
于是TD的值函数更新方式:
V(st)←V(st)+α(Rt+1+γV(st+1)−V(st))
其中:Rt+1+γV(st+1) 称为TD目标值,$\delta_t = R_{t+1}+\gamma V(s_{t+1})-V(s_t) $称为TD误差。
这种方法也叫TD(0)是TD(λ)的一种特殊形式。
Saras算法:
Q(s,a)←Q(s,a)+α(R+γQ(s′,a′)−Q(s,a))

Q-Learning算法:
Q(s,a)←Q(s,a)+α(R+γ maxa′Q(s′,a′)−Q(s,a))

0x06 资格迹
MC和TD的一个区别是,基于当前状态往未来看的距离不同。
MC:一直观测到结束,整个长度记为N。
TD: 长度是1,只参考了下一个状态的状态值。
能否够构造长度为d,(1≤d≤N)的值估计方法呢?
因此引入多步时序差分法(也叫资格迹法)
Gtn=rt+1+γrt+2+γ2rt+3+...+γn−1rt+n+γnV(st+n)
但是存在两种视角:
前向视角又叫理论视角,使用n个值来更新状态值,保证其权值和为1(资格迹的体现)。
TD(λ)前向算法
Gtλ=(1−λ)n=1∑∞λn−1Gtn
如果轨迹长度为T,则有(保证权重和为1):
Gtλ=(1−λ)n=1∑T−t−1λn−1Gtn+λT−t−1Gt
值函数更新如下:
V(st)←V(st)+α(Gtλ−V(st))
TD(λ)后向算法
资格迹需要考虑,导致这一状态产生的原因是多少来自频率、多少来自最近状态。
例如:连续三次拳击,接着一次电击,导致小狗死亡。
那小狗死亡原因,电击和拳击如何分配?
在t时刻的状态s对应的资格迹,记为Et(s):
E0(s)=0
Et(s)=γλEt−1(s)+I(St=s)
此方式被称为累计型资格迹,即状态被访问时,资格进行累加,不访问时退化。
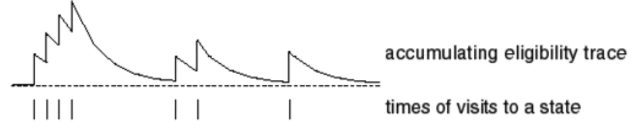
除了累计型资格迹,还有代替性资格迹:
Et(S)={γλEt−1(s),st=s1,st=s
TD误差更新如下:
δt=Rt+1+γVt(St+1)−Vt(St)
再结合资格迹更新状态价值,则有:
V(s)←V(s)+αδtEt(s)
Sarsa(λ) (后向)算法:
与传统的TD(λ)的不同之处是,本算法使用行为值函数:

本章访问状态时,资格迹+1主要是因为表格型问题,状态动作集合是可数的。
 wechat
wechat