Attention-Weighted Federated Deep Reinforcement Learning for Device-to-Device Assisted Heterogeneous Collaborative Edge Caching
衣带渐宽终不悔
为伊消得人憔悴~
0x00 Abstract
In order to meet the growing demands for multimedia service access and release the pressure of the core network, edge caching and device-to-device (D2D) communication have been regarded as two promising techniques in next generation mobile networks and beyond.
In this article, based on the flexible trilateral cooperation among user equipment, edge base stations and a cloud server, we propose a D2D- assisted heterogeneous collaborative edge caching framework by jointly optimizing the node selection and cache replace- ment in mobile networks.
Key Words: Edge Caching,D2D, Attention-weighted FL, DRL
0x01 INTRODUCTION
Innovative intelligent applications are highly dependent on the computation, storage and communication resources. The low latency for content access and diverse application requirements may not be satisfied if the contents are fetched from remote data centers (e.g., cloud server).
Mobile edge caching (MEC) has been regarded as a promising technique to relieve the burden of backhaul traffic for network operators.In terms of MEC, two key issues, i.e., node selection and cache replacement, need to be properly investigated.Moreover, some existing learning-based methods require users to send their personal data to the central server, which may cause serious issues of user privacy and security.
We are motivated to exploit the framework design of heterogeneous collaborative edge caching by jointly optimizing the node selection and cache replacement in D2D assisted mobile networks, and consider the flexible trilateral collaboration among UEs, BSs and the cloud server.
-
We formulate the joint optimization problem as a Markov decision process (MDP), and propose an attention- weighted federated deep reinforcement learning (AWFDRL) framework to address the problem.
-
It uses DQN to address the formulated long-term mixed integer linear programming (LT-MILP) problem
-
It employs FL to improve the training process by considering the limited computing capacity as well as the user privacy.
-
We employ an attention mechanism to control the model weights in the FL aggregation step, which can address the imbalance issue of local model quality.
There are many factors that can affect the attention weights and model quality.
We divide them into three categories as:
-
user- related factors such as user preference and personal habit;
-
device-related factors such as CPU capacity and RAM size which may effect the training batch size and replay memory size;
-
model-related factors such as model staleness and performance loss which can be calculated during the training process.
-
Note:base stations (BSs) 、user equipment (UE)
0x02 RELATED WORK
0x03 SYSTEM MODEL
A.Network Architecture
-
:表示流行的信息,每个数只是信息的id,并不是指信息本身,是指其信息大小
-
:用户设备的索引,是指设备可用存储
-
分别指本地基站和邻居基站
- 为了简化模型,只考虑一个邻居基站的情况
- 基站之间通过光纤通信,传输用户请求信息
- 可用存储是
-
有足够的容量存储的所有信息,与基站之间是 “backhaul links” 连接
-
分别指设备,本地基站,邻居基站有没信息
-
分别指设备,本地基站,邻居基站的缓存状态
B.Content Popularity and User Preference Model
-
利用
MZipf distribution计算每条信息的流行度:- 是流行度的倒序排名,是高原因数,是偏度因子 (防止流行度差距过大的??)
- 假设在一个相对较长的时间内,信息的流行度不会改变
-
用户偏好,用户对信息的请求在其总请求的占比表示其概率:
- 表示用户对信息的请求数
C.D2D Sharing Pattern
从物理维度和社会关系维度分析了用户间的距离,即可能进行信息共享的链路。最终通信图的边是物理维度与社会关系维度的交集。
物理维度:
考虑到信号强度等,只能在用户附近的用户的才可能从获取信息
社会关系维度:
Considering the selfish nature of human beings, mobile users with stronger social relationship are more willing to share their own content directly.
emmm,自私自利是人类的天性吗?
那为啥不考虑表面笑嘻嘻的假朋友呢?
-
通信图的定义:
注: 表示用户既相邻,又是朋友。
-
D2D信息共享的概率:利用
tanimoto coefficients计算- D2D信息共享的概率 ,,其中是归一化后的,
D.Content Transmission and Delay Model
:表示时间段
For each time slot , UE will send a request to access a content (say content ), and we denote to describe the request state at time .
对于每个信息的来源会有五种情况,延迟 会有很大差异,如下图所示,:
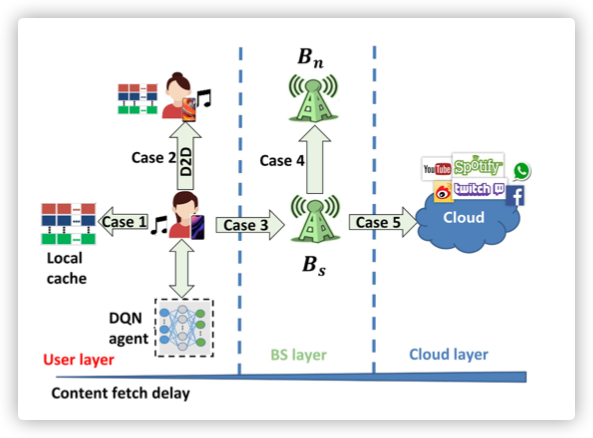
- Case 1:
Local cache - Case 2:
D2D - Case 3:
BSs - Case 4:
BSn - Case5:
Cloud
注:此处的 表示各信道的传输速率
一般有以下的关系:
其实个人感觉基站和D2D之间的关系有点迷。。。可能是书读的太少
0x04 PROBLEM FORMULATION
We formulate the joint problem of node selection and cache replacement in a UE as a Markov deci- sion process (MDP).
A. UE State
is the indicator on which node caches the requested content .
B.UE Action
UE decide where to fetch the content through the above methods and which content should be replaced in its cache list.
:从哪获取信息,:是否把信息加到缓存队列
C. System Reward
奖励分为D2D网络共享数据量和 信息共享延迟两个方面,前者需要最大化,后者需要最小化.
D2D Sharing Gain:
Content Fetch Gain:
- 其中是平均排队等待时间(为多个邻居共享信息,处理不及时,就会有排队情况)
- 应该是个平衡参数,防止的差距过大(差距过大,较小的那一项就起不到激励函数的作用,可以被砍掉)
System reward
D. Value Function
常规的价值函数

0x05 FRAMEWORK DESIGN OF AWFDRL
A. Whole Process
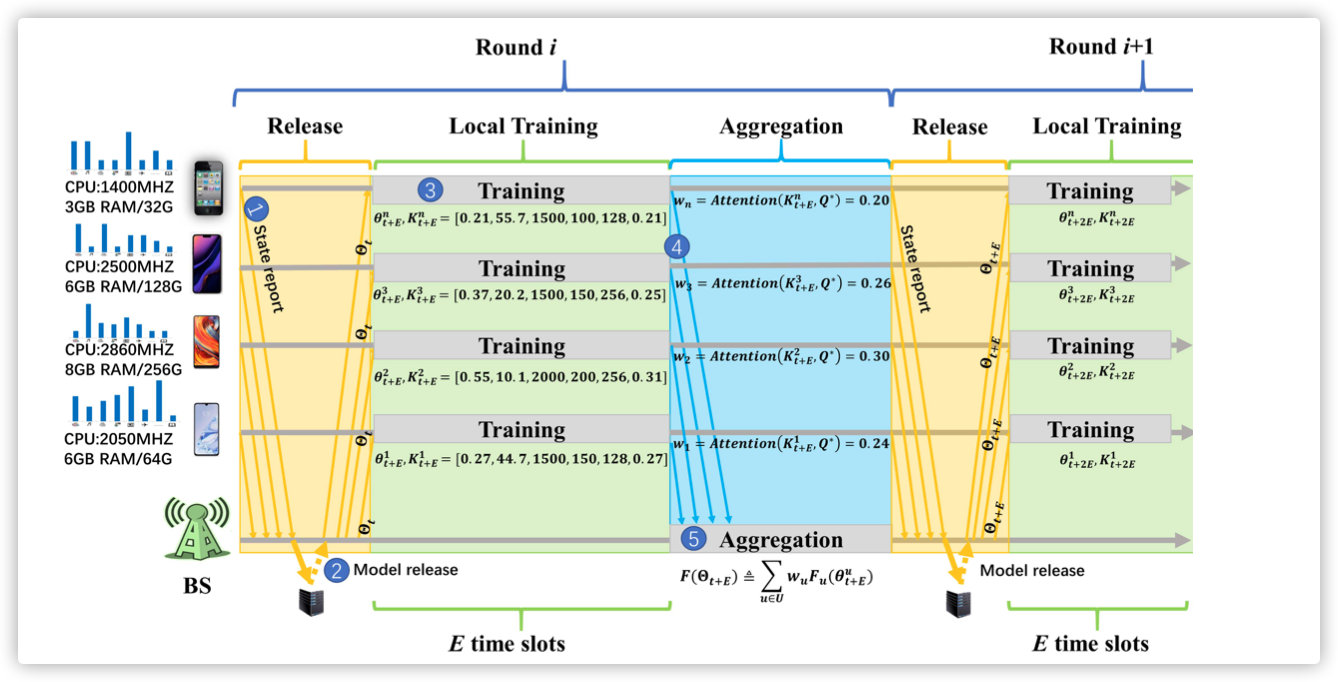
B.Local DQN Model Training
常见的DQN模型
实验中采用的是双层网络架构
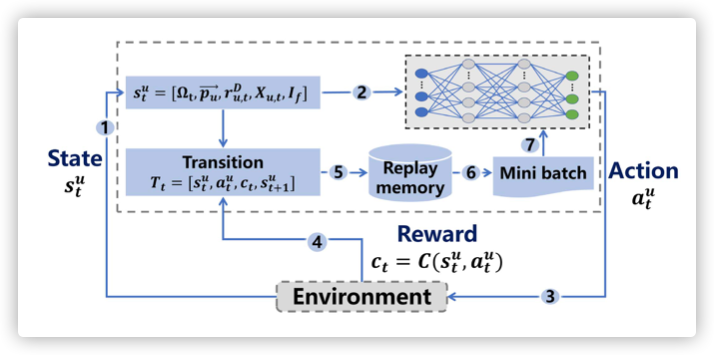

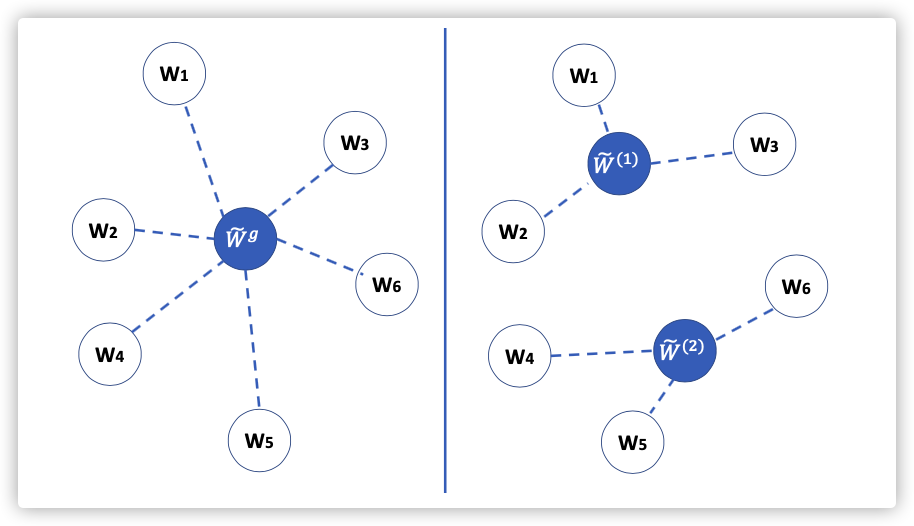
C.Weighted Federated Aggregation
考虑到训练节点的差异性,需要在模型聚合时,确定各模型的权重!
目标:确定
方法:Attention
考虑的信息为:
[Average reward,Average loss,Training data size,Episode number,Batch size,Hit rate]
- 计算方式:
D. Convergence Analysis
参考:
- MZipf distribution(齐夫定律)
- tanimoto coefficients
 wechat
wechat