Active Federated Learning
0x00 ABSTRACT
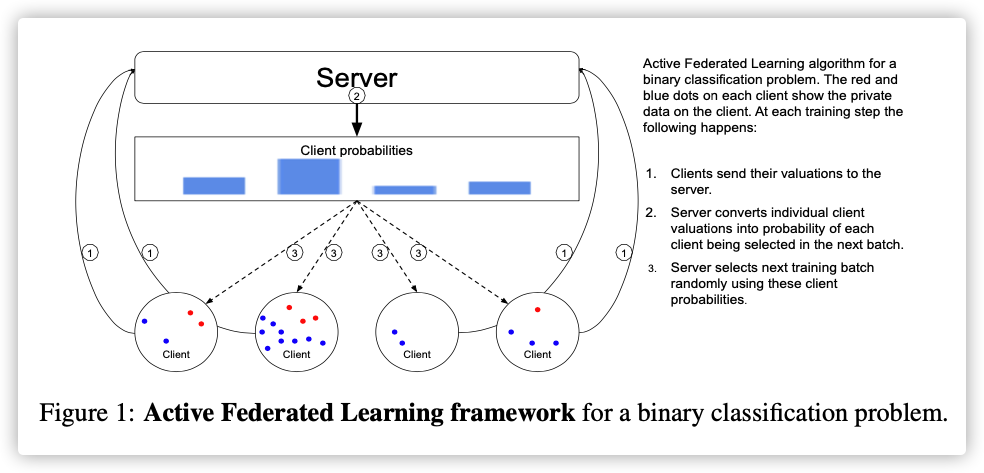
The data on each client is highly variable, so the benefit of training on different clients may differ dramatically. To exploit this we propose Active Federated Learning, where in each round clients are selected not uniformly at random, but with a probability conditioned on the current model and the data on the client to maximize efficiency.
Key Words: Active Learning, Federated Learning
0x01 Introduction
In this paper we introduce Active Federated Learning (AFL) to preferentially train on users which are more beneficial to the model during that training iteration.
Motivated by ideas from Active Learning, we propose using a value function which can be evaluated on the user’s device and returns a valuation to the server indicating the likely utility of training on that user. The server collects these valuations and converts them to probabilities with which the next cohort of users is selected for training.
0x02 Related Work
In both paradigms training data must be selected under imperfect information; in AL the covariates are fully known, but the label of candidate data points is unknown, whereas in AFL both labels and covariates are fully known on each client, but only a summary is returned to the server.
Additionally, in standard AL individual data points may be selected in an unconstrained manner, whereas in AFL we train on all data points on each selected user, creating predetermined subsets of data.
0x03 Background and Notation
Each user then performs some training using their local data and produce updated model parameter values .
In traditional Federated Learning the subsets are selected uniformly at random and independently at each iteration. Our goal in AFL is to select our subsets such that fewer training iterations are required to obtain a good model.
0x04 Active Federated Learning (AFL)
Inspired by the structure of classical AL methods, we propose the AFL framework which aims to select an optimized subset of users based on a function that reflects how useful the data on that user is during each training round.
价值函数:
-
要求:
- 与训练节点本地数据样本相关;
- 与全局模型相关;
- 对资源消耗小;
- 不能泄露数据太多信息;
-
返回值:一个实数
-
作用:作为下轮聚合节点选择依据
-
何时获取:由于价值函数与全局模型相关,为节省不必要的通信开销,只有节点被选中时,才会计算价值函数
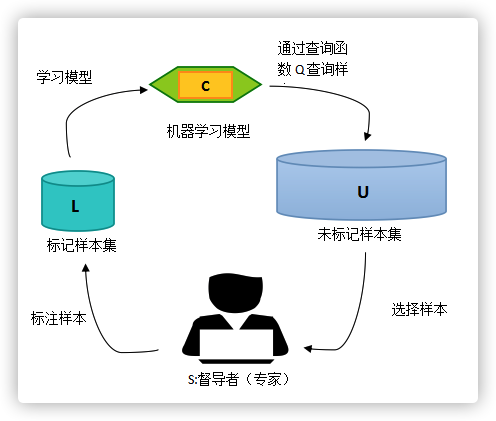
知识补充:主动学习(Active Learning)
记做:
解决大量数据集无label的情况!
根据部分标注label的数据集,训练出一个分类器。查询函数可从未标记数据集中查询信息量大的样本,将该类样本反馈给监督者,为其标注label。这是一个循环过程!
算法:

根据上面提到的,只有被选中的才会上传价值函数,为了防止进入局部最优,算法中会有一部分聚合节点采用随机选择!
概率根据
softmax设计。难点:的选取,没有依据决定,缺乏信服力!
1.Loss valuation
最常用的价值函数是损失函数!
注意!!!翻译过来的意思就是模型在节点表现越差,反而获得更大的权重!
If there is extreme class imbalance and weak separation of the classes, data points of the minority class will have significantly higher loss than majority class data points. Therefore we will prefer users with more minority data, mimicking resampling the minority class data.
Finally if all data points are equally valuable then users with more data will be given higher valuations.
这样的目的是为了充分学习少量数据的特征,但怎么证明损失函数不会出现反复横跳的情况?怎感觉和联邦学习的目标有点违背…
2.Differential Privacy
-
为了减少价值函数泄露的数据信息,可以考虑融入差分隐私。
-
但需要处理好,差分隐私的加噪不会对价值函数的分布产生太大的影响,误导中央服务器选择局部最优的节点!
-
解决方法的主要方向:
-
减少查询次数。损失函数这种值,一般不会发生骤变,所以查询前先询问是否发生骤变。
这个骤变怎么定义?联邦学习的模型聚合,模型骤变,损失函数很可能骤变啊
-
调整价值函数,使其更符合差分隐私。
-
0x05 Experimental Results
We compared AFL to the standard uniform selection on two datasets; one on the Reddit dataset, the other on the Sticker Intent dataset.
The task was binary classification - predict whether a message was replied to using a sticker.
-
-
The underlying model trained with Federated Learning used a 64 dimensional character level embedding, a 32 dimensional BLSTM, and an MLP with one 64 dimensional hidden layer.
-
The number of users in each Federated round was 200, and on each user 2 passes of SGD was performed with a batch size of 128. The learning rates for both local SGD and Federated ADAM were tuned separately for Random Sampling and AFL and the optimal learning rates were used for each.
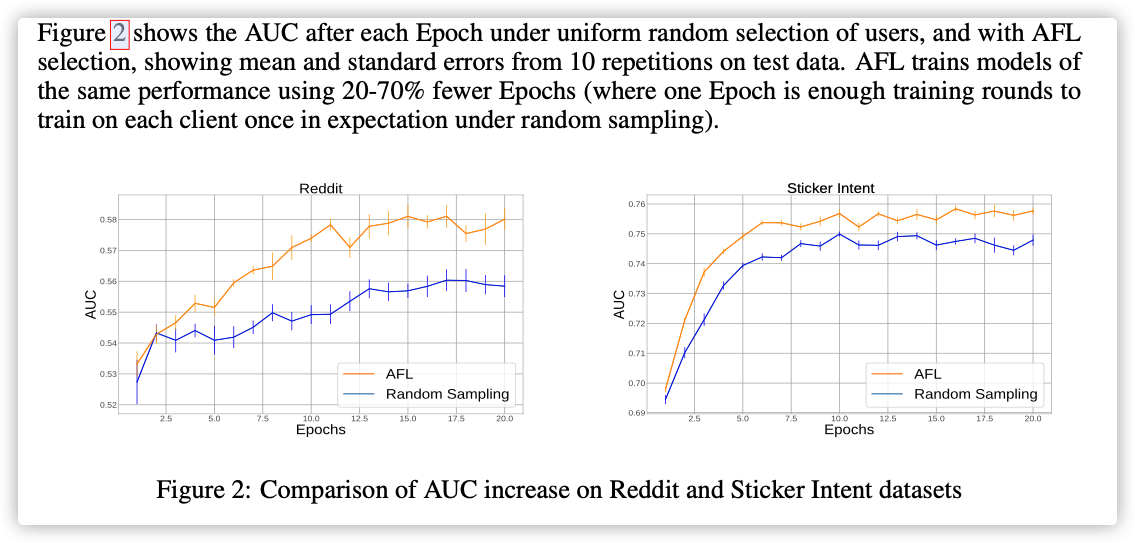
有点失望…
参考:
 wechat
wechat