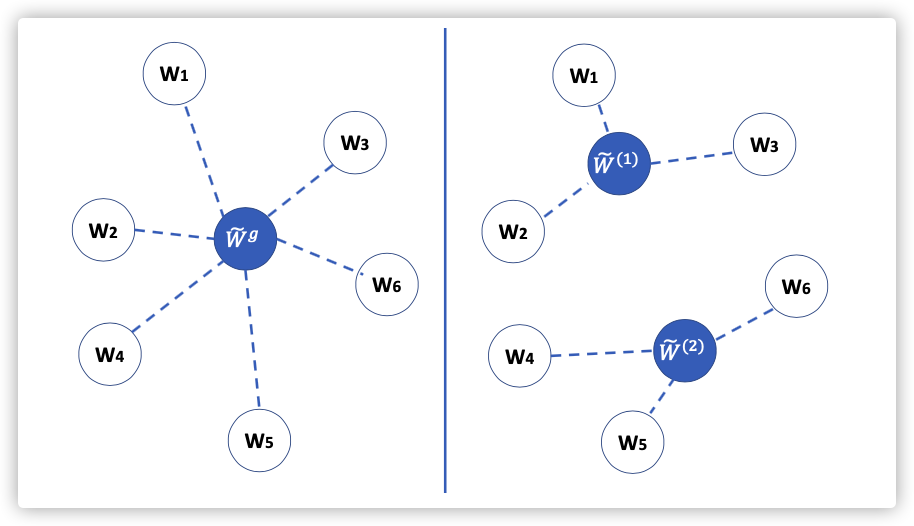
PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
目的:推测出数据分布相接近的节点,进行聚类。利用该集群对已有的全局模型进行参数微调,实现联邦个性化。
-
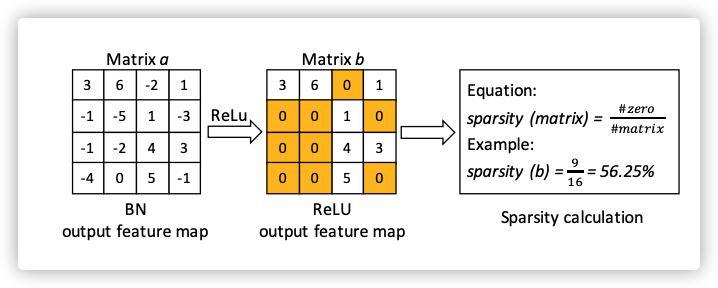
现在神经网络一般都会使用
ReLU作为激活函数,这样处理后的矩阵就会是系数矩阵。 -
利用该矩阵的稀疏度表示这个原始数据(用处理后的数据表示原始数据,保证了数据的隐私安全)
-
多个样本稀疏度的
均值,构成一个节点的稀疏度向量的一个元素。(向量的元素个数就是通道数) -
计算两节点的相似性:
其中:
q表示通道数E表示稀疏度向量,长度为q
-
为防止计算相似度矩阵耗费的时间复杂度,本文计算相似度过程如下:
- 挑选一个节点,计算其与其他节点的相似度向量:
- 如果很小,表示很相似
- 如果很接近,就说明很相似!!!!
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat
Related Articles