Reliable Federated Learning for Mobile Networks
0x00 Abstract
The workers may perform unreliable updates intentionally, e.g., the data poisoning attack, or unintentionally, e.g., low-quality data caused by energy constraints or high-speed mobility.
Based on this metric, a reliable worker selection scheme is proposed for federated learning tasks. Consortium blockchain is leveraged as a decentralized approach for achieving efficient reputation management of the workers without repudiation and tampering.
Key Words:Federated learning, consortium blockchain, reputation management, mobile networks.
0x01 INTRODUCTION
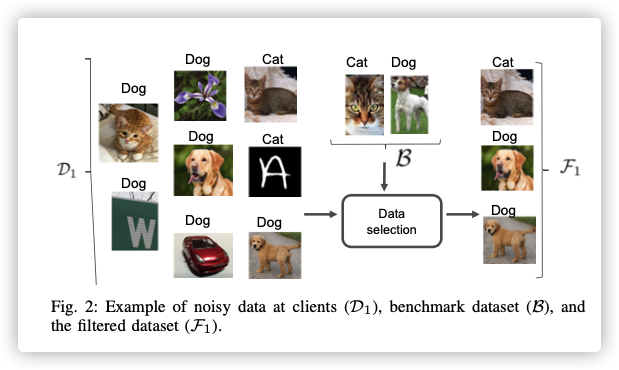
During a federated learning process, data owners may mislead a global model by intentional or unintentional behaviours. For intentional behaviors, an attacker can send malicious updates, i.e., the poisoning attack, to affect the global model parameters resulting in the failure of current collaborative learning. In addition, much more dynamic mobile networking environments indirectly result in some unintentional behaviors of data owners.
It is of paramount importance for federated learning to defend against such intentionally and unintentionally unreliable local model updates.
We propose that reputation can be used to provide solutions to select reliable and trusted workers for the federated learning tasks.
- Existing studies show that reputation can reflect the rating of how reliable or trusted an entity is in certain activities according to its historical behaviors.
- Each task publisher calculates reputation opinions of every interacting worker through a subjective logic model.
- In the subjective logic model, the task publishers integrate their own opinions based on past interactions and recommended opinions from other task publishers .
- All the reputation opinions of the task publishers for the workers should be recorded in a non-repudiation and tamper-resistance manner for reliable reputation calculation.
- To realize reliable reputation calculation as well as reputation management in federated learning, we design a consortium blockchain acting as a trusted and decentralized ledger to record and manage the data owners’ reputation.
Main contributions:
- To defend against unreliable model updates, reputation is introduced as a reliable metric to select trusted workers for reliable federated learning.
- A multi-weight subjective logic model is applied to design an efficient reputation calculation scheme according to both task publishers’ interaction histories and recommended reputation opinions.
- To achieve secure reputation management, the reputation is managed in a decentralized manner by employing the consortium blockchain deployed at edge nodes.
0x02 FEDERATED LEARNING AND ITS VULNERABILITIES
A. Mobile Applications
- Google keyboard
- Service recommendation
- Traffic monitoring and prediction
- Mobile healthcare
B. Security Challenges and Motivations
On the one hand, due to the openness and complexity of mobile network architectures, the data owners performing maliciously unreliable updates may result from:
- sensing data from malicious intent or tampered devices may include deceptive information, which is similar to false data injection attacks in smart grids;
- the data can be arbitrarily manipulated when being transmitted through insecure communication channels
If a malicious data owner is selected to be a worker, the malicious worker may intentionally launch or collude with other workers to launch attacks, such as poisoning attacks.
On the other hand, the data owners may inadvertently provide unreliable local update from low-quality raw data because of energy constraints or high-speed mobility.
Both the intentional and unintentional behaviors can degrade the quality of the global model managed by a central aggregator , hence affecting the final outputs of the global model.
The following challenges for the worker selection need to be addressed:
-
No reliable and fair metrics to evaluate workers:
The existing schemes cannot measure the trustworthiness level of workers to remove unreliable or untrusted workers.
-
No efficient and universal worker selection schemes:
It is difficult to design an efficient and universal worker selection scheme for identifying high-quality data contributors and malicious worker candidates.
-
No timely monitoring methods for workers:
It is hard for the central aggregator/server (i.e., task publisher) to monitor the large-scale worker behaviors in real-time.
0x03 REPUTATION MANAGEMENT
A. Overview of Reputation Management in Crowdsensing
Reputation:
在移动群智感知(Crowdsensing)中,荣誉机制被用于选择高数据的提供者。节点的荣誉值是根绝其历史贡献获得、更新的。
PS:Crowdsensing 也是利用大量设备共同完成同一任务
本文引入荣誉值,也是为了选择可靠的训练节点。
为了避免中心化荣誉值计算的潜在风险,本文设计了一个去中心化的荣誉计算方式(Subjective logic model),并结合联盟链(consortium blockchain)实现荣誉机制的安全管理。
B. Reputation-based Worker Selection Scheme with Consortium Blockchain
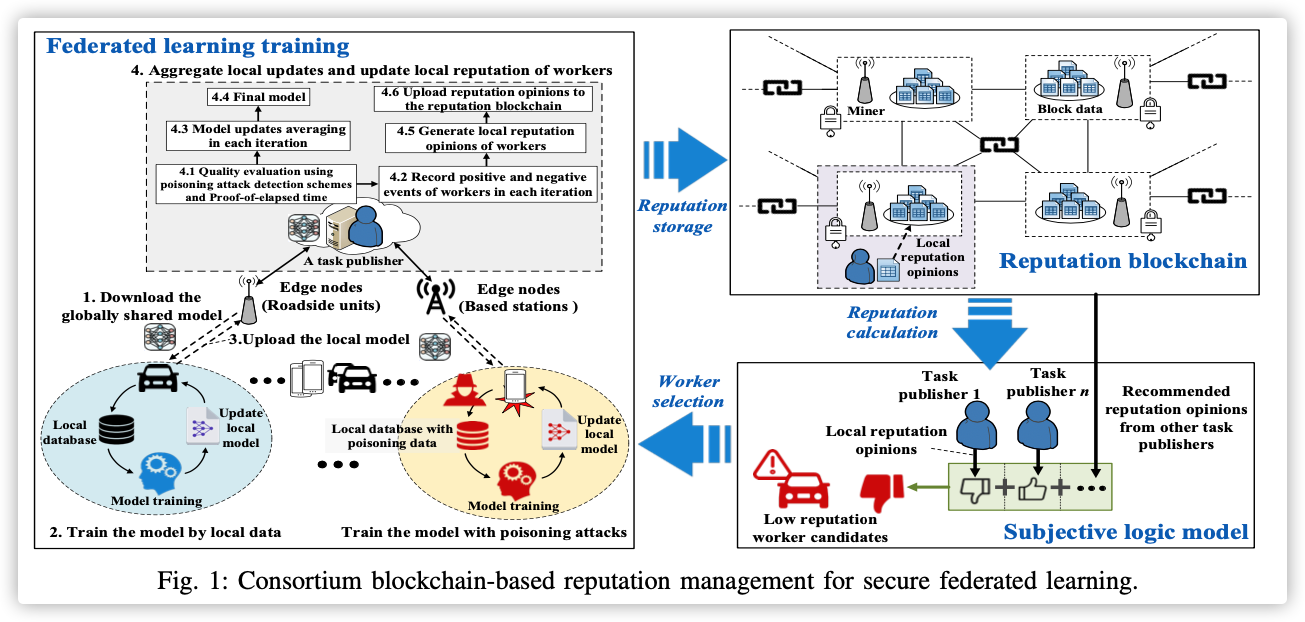
主要过程如下:
-
Step 1:
Task publishment任务发布者下发任务,满足数据要求的移动设备如果想参加,就将参加请求和身份、数据资源信息发送给任务发布者。
个人观点:这里的数据资源信息,应该只是本地原始数据的一种概要,并不是真正的数据
-
Step 2:
Worker selection任务发布者根据回收的消息进行节点选择:
-
根据subjective logic model进行荣誉值的计算,超过任务荣誉阈值的节点才会被选中
-
任务发布者可以根据任务需要的安全等级设置不同的荣誉阈值
Q:这个阈值要怎么设置呢?
-
-
Step 3:
Reputation calculation荣誉值由
local reputation opinions和recommended reputation opinions两部分共同决定:-
recommended reputation opinions:以往的任务发布者对该节点的"服务质量评价",该评价被会存储在联盟链(reputation blockchain)上,供所有任务发布者参考。 -
local reputation opinions:当前任务发布者对该节点在此次任务中历史表现,直接观测该节点的好坏。此部分由三个参数组成!
可以和外卖结合起来,推荐值就是其他人对此外卖的好评度等标准。至于后者,就是亲自点外卖试试,看看是不是像其他人口中评论的那样好吃,毕竟存在自己被坑了,也希望别人被坑的人!(防止其他任务发布者的合伙欺诈)
Q:local reputation opinion能否存在更合适的构成方式?
-
-
Step 4:
Federated learning-
使用了
SGD的优化器。 -
要求训练节点将
本地计算时间上传,根据时间和数据量推断该节点是否在训练过程"偷懒"。为了保证该时间的真实性,可以考虑Intel's SGX -
为了防止数据投毒,可以结合相应的方法:
- Reject on Negative Influence (RONI) scheme for IID(本文考虑的情况)
- FoolsGold scheme for non-IID
-
训练节点完成任务可以获得奖励
用时间和数据推断是否偷懒,还需要考虑到设备的差异性,万一高性能手机就是计算快呢?
感觉使用
IID的数据做实验,是一种残缺… -
-
Step 5:
Reputation updating预选准备矿工,会将本次节点与任务发布者的交互情况和本地荣誉值上传到荣誉链上!
所有的任务发布者可以访问参考!
不太了解联盟链,但是感觉既然是矿工,还是需要奖励机制,这又是一笔开销。。。
0x04 EFFICIENT REPUTATION CALCULATION SCHEME
一个三元组表示 opinion:(belief,distrust,uncertainty)
Every task publisher selects workers by calculating composite reputation values according to its local reputation opinion and recommend reputation opinions.
A. Subjective Logic Model for Reputation Calculation
By using poisoning attack detection schemes and the proof of elapsed time scheme (Step 4 in Section III-B), the task publisher treats a training iteration as a positive interaction event if the publisher perceives that the local model update from a worker is reliable, and vice versa.
-
uncertainty degree: 是个概率,表示之间链路的通信质量 -
belief degree: -
distrust degree:其中分别表示 positive,negative的交互数量,的总和是1。
From the local opinion vector, a local reputation value is generated to represent the task publisher’s expected belief that the worker provides high-quality local model updates during the federated learning.
Local reputation value: ,其中为给定的常数,表示不确定性对本地荣誉值的影响程度
B. Multi-weight Subjective Logic Model
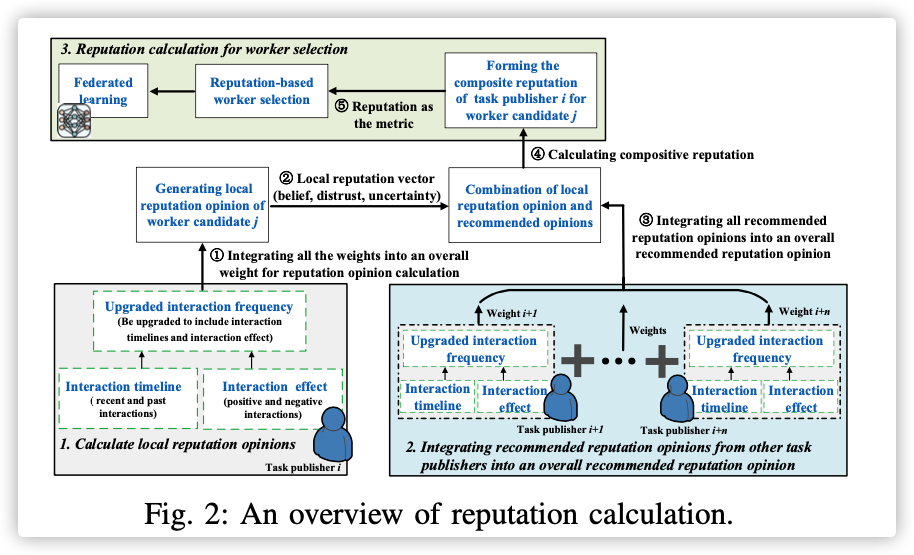
本节的目的就是确定
local reputation value在合成最终的reputation opinion时的权重!
本文主要考虑了三个方面:
-
Interaction Frequency: 一个时间窗口内,该节点与任务发布者的交互次数与其他节点和任务发布者交互次数的均值的比值。
交互次数越多,说明带给任务发布者的有用信息越多,所以可以有一个较高的本地荣誉值
-
Interaction Timelines: 一个时间线,时间线之前为
过去交互,时间线以内为近期交互考虑到训练节点可能会被攻击,发生叛变,因此可信程度和本地荣誉值要随时间改变。
在计算荣誉值时,近期交互会有一个较高的权重(仍然考虑过去交互)
-
Interaction Effects: 给交互体验打分,正数()越多,就会有越高的权重。
Taking the interaction timelines and interaction effects into consideration, the interaction frequency is upgraded to contain the above two weights. Therefore, the interaction frequency is determined by both the two weights and the average number of times of interactions with other workers during a time window. After that, the upgraded interaction frequency is used to generate an overall weight for local and recommended reputation opinion calculation.
下图中①②的过程:
C. Recommended Reputation Opinions
根据权重,将其他任务发布者给的本地荣誉值整合成一个推荐荣誉值。(该权重就是上述B过程计算的)
These degrees are calculated by weighted arithmetic mean of the belief degrees, distrust degrees and uncertainty degrees from other task publishers, respectively.
D. Combining Local Reputation Opinions with Recommended Reputation Opinions
When calculating the composite reputation value of a worker, the task publisher takes not only the overall recommended opinions, but also its own local reputation opinion into consideration to avoid collusion cheating from other task publishers.
至于 composite reputation value 具体的计算过程,在本文作者的其他论文中给出:
- “Towards secure blockchain-enabled internet of vehicles: Optimizing consensus management using reputation and contract theory”
- “Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory”
解释为什么要这么做:
These high-reputation workers will train local model honestly and maintain good behaviors in the federated learning tasks for earning more profits from the system. Therefore, the reputation-based worker selection scheme can defend against unreliable local model update from intentional or unintentional data providers, hence ensuring reliable federated learning in mobile networks.
这个地方要是数学的严格证明,效果会更好!
0x05 NUMERICAL RESULTS
A. Simulation Setting
-
DataSet:
MNIST -
TensorFlow:
1.12.0 -
Worker_Num:
10- malicious workers:
2 - unreliable workers:
4 - well-behaved workers:
4
- malicious workers:
-
Data Distribution:
- For the malicious workers launching poisoning attacks, they randomly receive training data with 10 classes. However, the labels of some training examples are intentionally modified for misleading training. The percentage of the modified training examples is used to indicate the attack strength.
- The training sets of the well-behaved workers are randomly assigned but follows a uniform distribution over 10 classes.
- The data in each unreliable worker is only assigned a certain number of classes randomly.
-
We employ the Earth Mover’s Distance (EMD) as a metric to measure training data quality of the unreliable workers.
-
The workers use a batch of 32 randomly sampled training examples to produce a local SGD update, and every global model is trained with 5 synchronous iterations
-
We establish the reputation blockchain system on the Hyperledger Fabric v1.4.0 and use the practical and efficient PBFT algorithm with mild overhead and latency as the consensus algorithm.
-
reputation calculation:
- the interaction frequency between task publishers and workers is from 20 to 40 federated learning tasks every week.
- The weight parameters of negative, positive, recent, and past interactions, and the time scale in the proposed Multi-weight Subjective Logic (MSL) scheme are referred to this paper.
- The unsuccessful transmission probability of data packets ranges from 0% to 40%, and the initial reputation of all the workers is 0.5 .
B. Performance Results
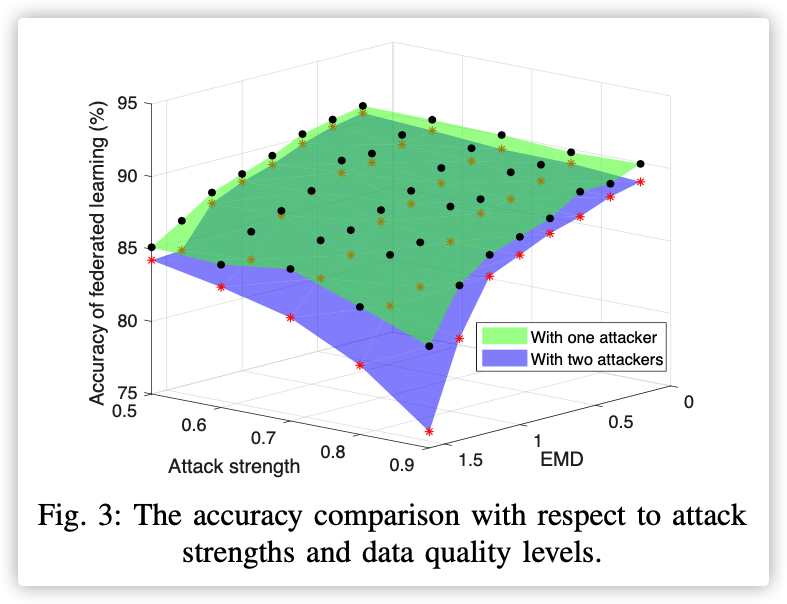
感觉像是意料之中的结果…
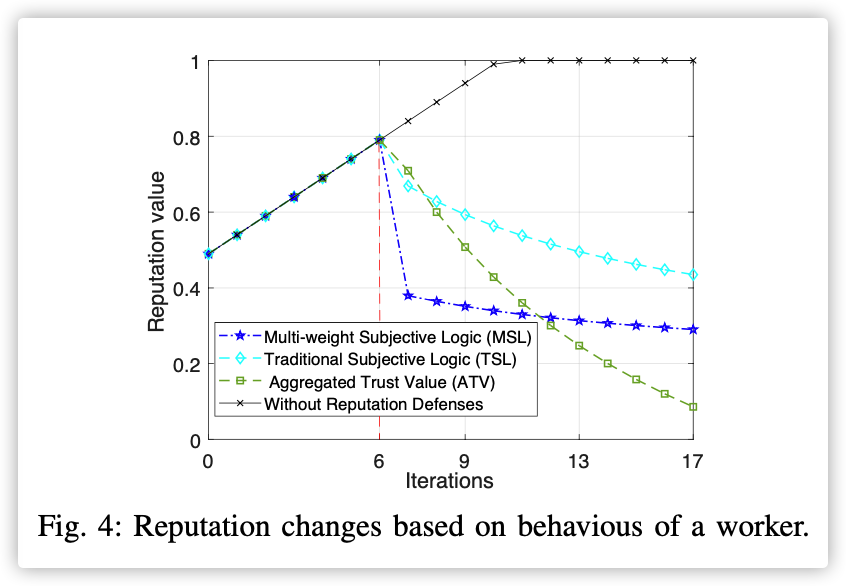
这个图就是展示了训练节点 叛变的情况!一开始荣誉值会增加,后面叛变了,所以荣誉值会下降。此时模式能迅速下降…
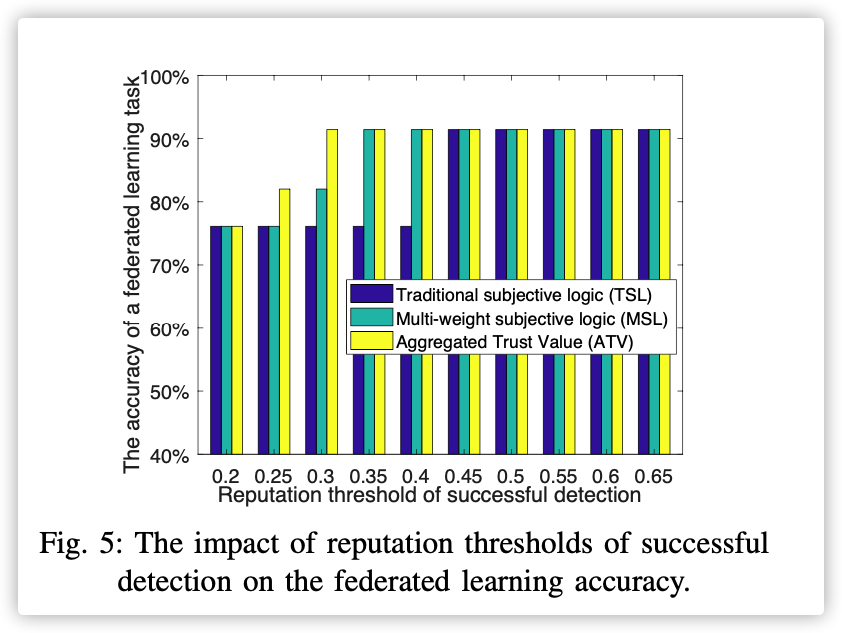
In summary, the MSL scheme can achieve a more accurate and fair reputation calculation, thereby leading to a more reliable worker selection in federated learning.
看图5比较尴尬的是,本文提出的模型没有什么比较出色的表现…
个人观点:
终端荣誉机制就好比文章用到的区块链机制,要想有人为算力买单,就要将荣誉机制和切实利益相挂钩,这也是联邦学习从理论向实际转变必须要面临的问题!
 wechat
wechat