FedMD: Heterogenous Federated Learning via Model Distillation
0x00 Abstract
Federated learning enables the creation of a powerful centralized model without compromising the data privacy of multiple participants. While successful, it does not incorporate the case where each participant independently designs its own model.
In this work, we use transfer learning and knowledge distillation to develop a universal framework that enables federated learning when each agent owns not only their private data, but also uniquely designed models.
Key Words: Transfer Learning,Knowledge Distillation,Model Heterogeneity,Federated Learning
0x01 Introduction
There is system heterogeneity when each participant has a different amount of bandwidth and computational power; this was partly resolved by the native asynchronous scheme of federated learning, which was further refined e.g. to enable active sampling and improve fault tolerance .
There is also statistical heterogneity (the non IID problem) where clients have a varying amount of data coming from distinct distributions.
We focus on a different type of heterogeneity: the differences of local models.
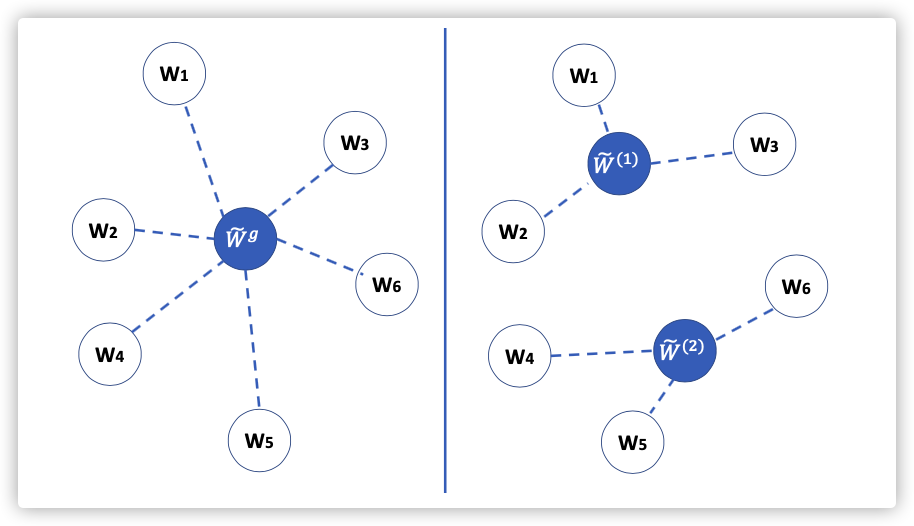
In this work, we instead explore extensions to the federated framework that is realistic in a business facing setting, where each participant has capacity and desire to design their own unique model. This arise in areas like health care, finance, supply chain and AI services.
Application scenarios:Federated Learning for Business(High-performance computer)
Main Methodology:
-
Knowledge distillation:
There must be a translation protocol enabling a deep network to understand the knowledge of others without sharing data or model architecture.
-
Transfer learning:
- First, before entering the collaboration, each model is fully trained first on the public data and then on its own private data.
- Second, and more importantly, the blackbox models communicate based on their output class scores on samples from the public dataset.
Contributions:
- FedMD,a new federated learning frame- work that enables participants to independently design their models.
- Centralized server does not control the architecture of these models and only requires limited black box access.
- A key element for translating knowledge between participants.
- We implement such a communication protocol by leveraging the power of transfer learning and knowledge distillation.
0x02 Methods
Problem definition
-
小规模隐私数据集,大规模共享数据集
-
每个参与训练节点自定义模型,模型架构可以不同,超参不共享
-
目标:与其他节点聚合后的模型比只用训练的模型性能好即可。
目标的就是说明联邦还是有作用的就行。。。
FedMD Algorithm

Transfer Learning:利用训练至收敛的模型,在上面接着训练。
Communication:防止过大的通信开销,每次获得只用的部分数据。
Q&A:
class score是什么?从后续方法看,应该是
logits怎么训练逼近?
Knowledge Distillation
0x03 Results
-
数据集:
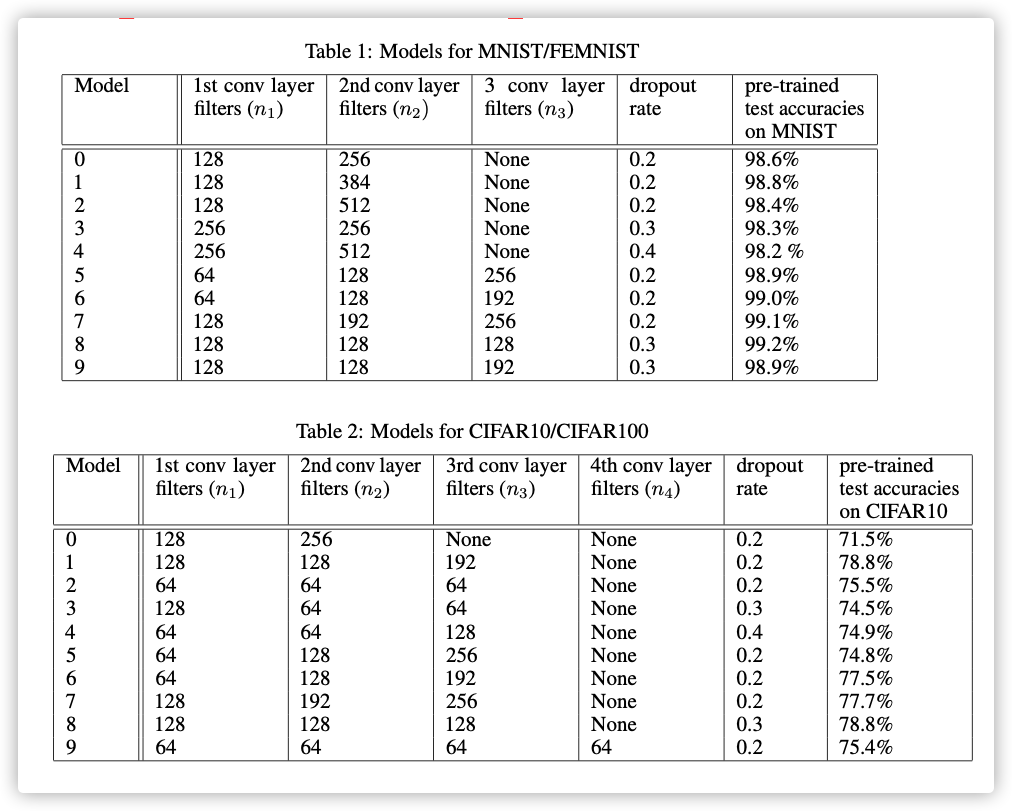
- In the first environment, the public data is the MNIST and the private data is a subset of the FEMNIST.
- In the second environment, the public dataset is the CIFAR10 and the private dataset is a subset of the CIFAR100, which has 100 subclasses that falls under 20 superclasses,e.g. bear, leopard, lion, tiger and wolf belongs to large carnivores.
-
Non/IID
- We consider the IID case where each private dataset is drawn randomly from FEMNIST, as well as the non-IID case where each participant, while only given letters written by a single writer during training, is asked to classify letters by all writers at test time.
- In the IID case, the task is for each participant to classify test images into correct subclasses. The non-IID case is more challenging: during training, each participant has data from one subclass per superclass; at test time, participants need to classify generic test data into the correct superclasses.
-
节点数量:
10 -
网络模型:
-
优化器:
Adam,学习率0.001 -
打分样本:
5000(这个属实有点大) -
结果如下:


 wechat
wechat