Federated Learning with Non-IID Data
好久没看论文了,菜是原罪。。。
0x00 Abstract
本文专注于FL中Non-IID的统计困难问题。
用训练节点种类分布的Earth mover’s distance(EMD)量化权重差异度,以此来说明准确下降的问题。
提出了一种数据分享的策略:中央云端共享数据集到各个训练节点!
KEY WORDS:Non-IID,Weight Divergence,EMD
0x01 Introduction
-
IID数据比较容易训练:
The IID sampling of the training data is important to ensure that the stochastic gradient is an unbiased estimate of the full gradient
0x02 FedAvg on Non-IID data
Setup
训练节点:10
数据集:MNIST、CIFAR-10、KWS
数据分布:
- IID:each client is randomly assigned a uniform distribution over 10 classes.
- Non-IID
1-class non-IID, where each client receives data partition from only a single class2-class non-IID, where the sorted data is divided into 20 partitions and each client is randomly assigned 2 partitions from 2 classes.
FedAvg算法参数:
B, the batch size and E, the number of local epochs. The following parameters are used for F edAvg:
for MNIST, B = 10 and 100, E = 1 and 5, η = 0.01 and decay rate = 0.995;
for CIFAR-10, B = 10 and 100, E = 1 and 5, η = 0.1 and decay rate = 0.992;
for KWS, B = 10 and 50, E = 1 and 5, η = 0.05 and decay rate = 0.992.
Results
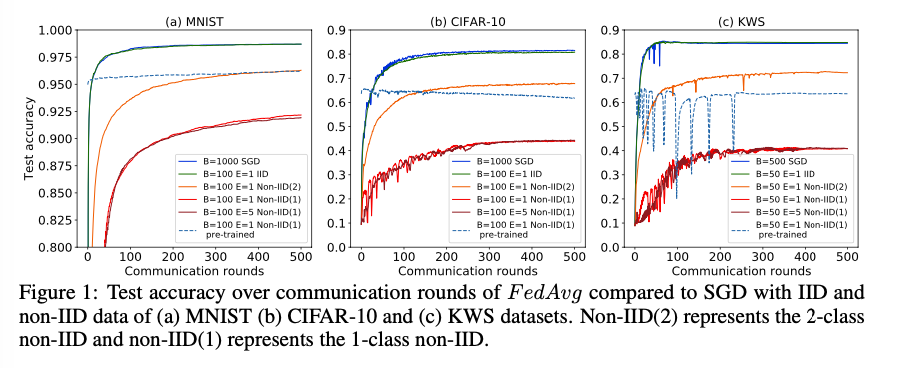
准确度对比:
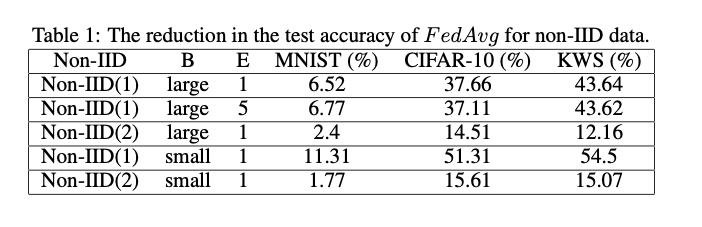
两种Non-IID性能损失对比:
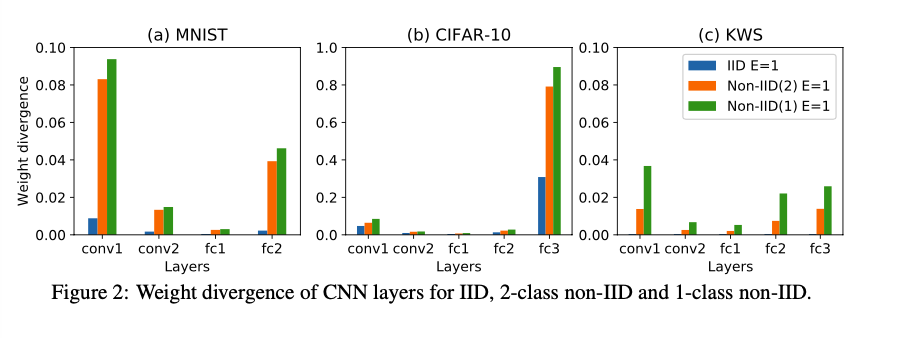
0x03 Weight Divergence due to Non-IID Data
权重差距定义如下:
数学证明:
复杂。。。
0x04 Proposed Solution
The local model of each client is trained on the shared data from G together with the private data from each client.
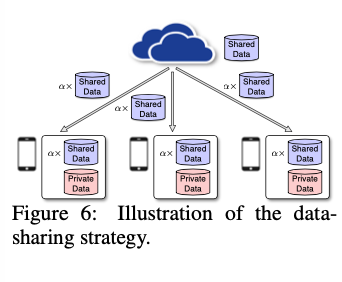
但是会迎来两个Trade-off:

参考:
 wechat
wechat