Advances and Open Problems in Federated Learning
一篇超长综述,不过这应该是假期前讲的最后一部分了 (~ ̄▽ ̄)~
0x00 Abstract
Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
KEY WORDS:Federated Learning,Efficiency,Privacy,Robustness
0x01 Introduction
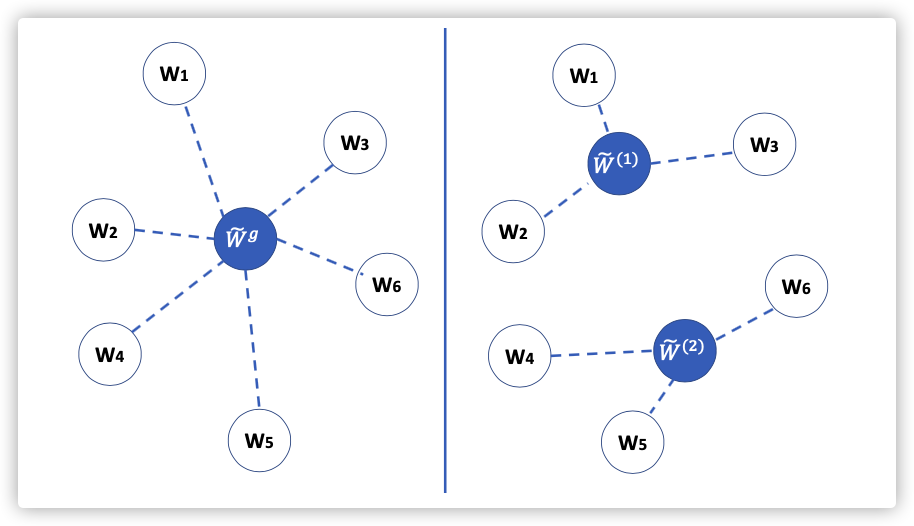
0.三者对比
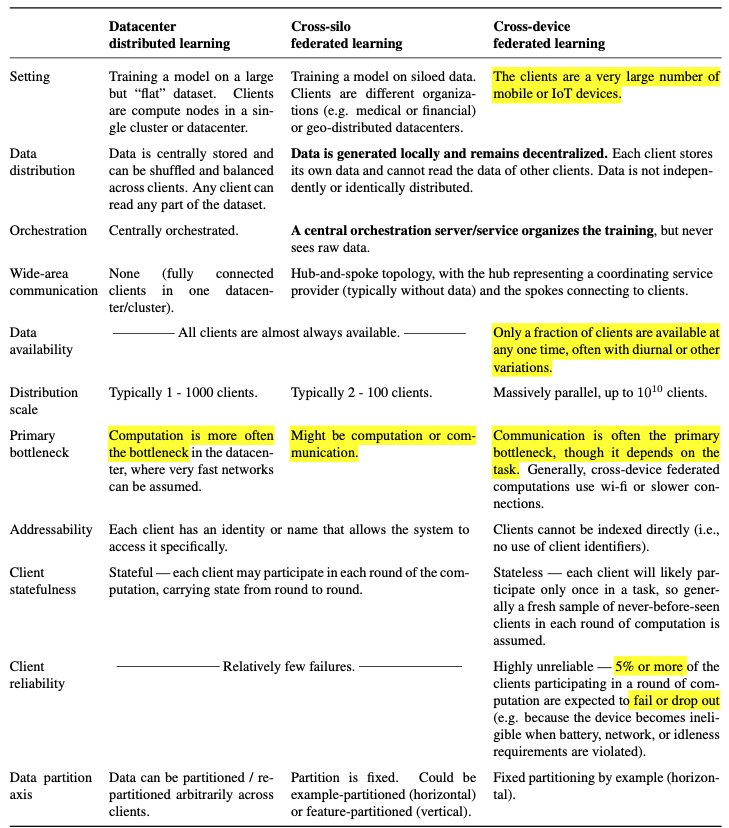
本文主要讨论跨设备的FL。
1.跨设备联邦学习
-
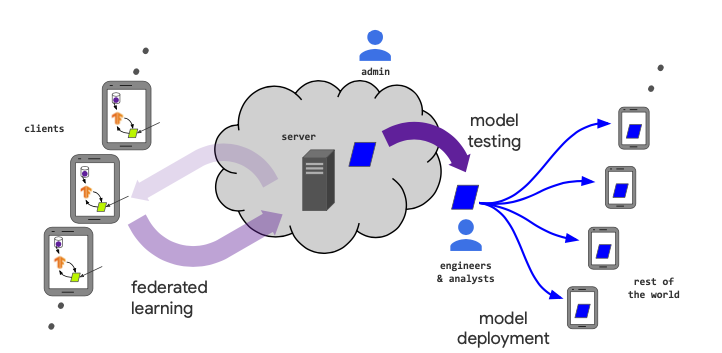
生命周期:
-
工作流程:
- 问题定义
- 客户端指令:客户端收集、标记、存储训练数据。
- 模拟测试(可选):模型工程师使用代理数据进行模型原型设计和测试超参。
- 联邦模型训练
- 联邦模型评估:可以数据中心评估、客户端评估。
- 部署:包括扩展性测试等。
-
联邦模型训练:
- 节点选择
- 参数下发
- 节点训练
- 参数聚合
- 模型更新
传统训练数量级:

两个需要注意的方面:
- 训练时的模型不要向用户展示预测结果。
- 不能影响用户的正常设备使用。
2.联邦学习的研究
本文基于医院药物数据训练实验,涉及到上亿台设备。
联邦学习的实验实施困难,这就导致从经验角度研究FL比其他ML困难很多。
对于解决问题提出的一些建议:
- 见表一的一些设置。
- 仿真实验细节要写明,做到可复现。
- 隐私和通信效率要放在首位。
0x02 Relaxing the Core FL Assumptions: Applications to Emerging Settings and Scenarios
1.Fully Decentralized / Peer-to-Peer Distributed Learning
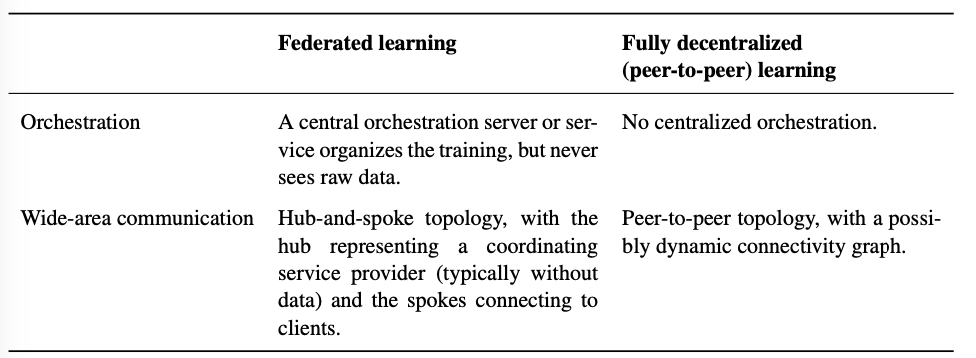
Fully Decenteralized learning 需要面对一些困难,比如:用什么模型、算法、超参?出错时,谁负责调试?
A certain degree of trust of the participating clients in a central authority would still be needed to answer these questions. Alternatively, the decisions could be taken by the client who proposes the learning task, or collaboratively through a consensus scheme
(分散、缺少信任机制)
算法困难
-
Effect of network topology and asynchrony on decentralized SGD
网络线路不可靠,数据受损会被抛弃。
网络稠密图中,收敛快,延迟高。
MATCHA算法:分解网络稠密图,选择部分链接子集,实现并行;在重要部分通信更多,确保收敛更快,其他地方通信更少,节省通信延迟。
Decentralized SGD可以用于异步更新。
-
Local-update decentralized SGD
本质上还是讨论Local SGD在non-IID数据上的收敛问题。
明白non-IID数据分布式部署的情况下收敛情况、如何设计聚合策略达到更快的收敛是一个开放问题。
-
Personalization, and trust mechanisms
设计学习个性模型的算法也很重要。
模型的健壮性:恶意参与者、数据投毒。
-
Gradient compression and quantization methods
如何将中心联邦结构的梯度压缩和量化技术不产生副作用的应用于完全去中心化联邦学习?
实际困难
- 在完全去中心化联邦学习中,可以参考区块链的智能合约;
- 区块链的数据可以公共访问,与FL的隐私保护相违背;
- FL保护模型需要安全聚合、处理掉线设备
- FL防止恶意参与者重构其他参与的隐私数据,需要使用客户端差分隐私(添加高斯噪声)
2.Cross-Silo Federated Learning
虽然Cross-Silo FL 条件比Cross-Device FL宽松,但也要一些要求很难达到。
与企业组织的共享激励机制有关。(激励客户将其数据用于训练)
Data partitioning
- 可以按照样本划分(横向)、特征划分(纵向)
- (特征划分)基于特殊训练算法,可能需要一个中心服务器作为中立派。
- 客户端与之交换中间结果而不是模型参数,帮助其他参与者进行梯度计算。
- 安全多方计算和同态加密用于保护中间结果,不被数据反推。
- 联邦迁移学习:只共享一部分用户空间或特征空间。
- (样本划分)受限于法律不能整合数据,不同组织之间协作训练,如不同银行诈骗检测,医院病情诊断。
- 开源平台:FATE
Incentive mechanisms
对参与者奖罚分明,激发参与积极性。
- 根据参与者对模型的数据贡献划分奖励,维持长期参与
- 奖励要与捍卫系统安全、优化系统效率相结合。
Differential privacy
- 第四部分参与者与威胁模型会仔细讨论跨孤岛FL。
- 防范不同参与者会有不同的优先级。
- 本地差分隐私:防范其他客户端的威胁。
- 用户级隐私保证。
Tensor factorization
- 多网站执行张量分解、并与协调服务器共享中间因子,保证数据隐私。
- 现有方法:ADMM、EASGD(提高效率)
3.Split Learning
将模型的训练过程划分,部署到不同的设备进行训练。
-
数据传播:
-
前向传播没有共享原始数据。
-
反向传播,只有cut layer的梯度传给客户端。
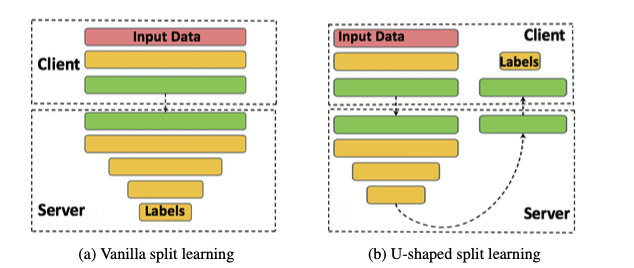
-
-
常规设置:
-
引入训练过程的另一并行维度,例如客户端-服务端
-
开放问题:边缘设备上Split Learning的并行问题
-
模型自动选择:客户端模型部分匹配服务端最佳模型部分。
-
-
安全问题:
- 根据交流数据反推数据
- NoPeek SplitNN:通信激活减少原始数据的相关性,分类交叉熵保证模型性能。
- NoPeek SplitNN核心思想:最小化原始输入数据与传输数据的相关性。
0x03 Improving Efficiency and Effectiveness
本节讨论如何提高效率,方法多种多样:优化算法、为不同设备提供不同模型、ML用于FL的调参建模调试、提高通信效率等。
1.Non-IID Data in Federated Learning
不同的用户、不同的地区、不同时间等因素,导致数据非独立同分布。就算是和用户间序列相关的数据集也可以通过本地打乱实现非独立同分布。
Problems with Non-IID Data
Non-identical client distributions:
Rewriting as and。
Feature distribution skew (covariate shift):相同,随节点变化
Label distribution skew (prior probability shift):相同,随节点变化
Same label, different features (concept shift):相同,随节点变化
Same features, different label (concept shift):相同,随节点变化
Quantity skew or unbalancedness:不同节点,不同数据集
在真实环境数据集划分中如何刻画不同的设备是一个开放问题。
Violations of independence:
- 参与训练的设备集发生变化,打破了原有的Non-IID数据集。
Dataset shift:(个人理解是,训练机和部署机不同导致模型扩展性降低的问题)
- Q和P分布的时间依赖性会导致数据偏移。
- 如何处理数据偏移是一个开放问题。
Strategies for Dealing with Non-IID Data
为了效率常见方式:修改现有算法、设计新算法
- 增加数据。使不同设备上的数据更相似。
- 客户异质性需要重视目标函数的设计。
- 本地训练。可以实现定制化模型,这就将non-IID的缺点转化成优点;也能解决客户可用性变化导致的独立性改变带来的问题。
2.Optimization Algorithms for Federated Learning
算法:
- 无状态。
- 与其他技术相结合。
- 现有算法:FedAvg & local SGD ==>满足数据本地限制和通信限制。
- 专门针对FL环境特征的新算法的开发仍然是一个重要的开放问题。
Optimization Algorithms and Convergence Rates for IID Datasets
- 每轮中固定x,使用mini-batch SGD计算次梯度。
- 每轮只关注M个客户端
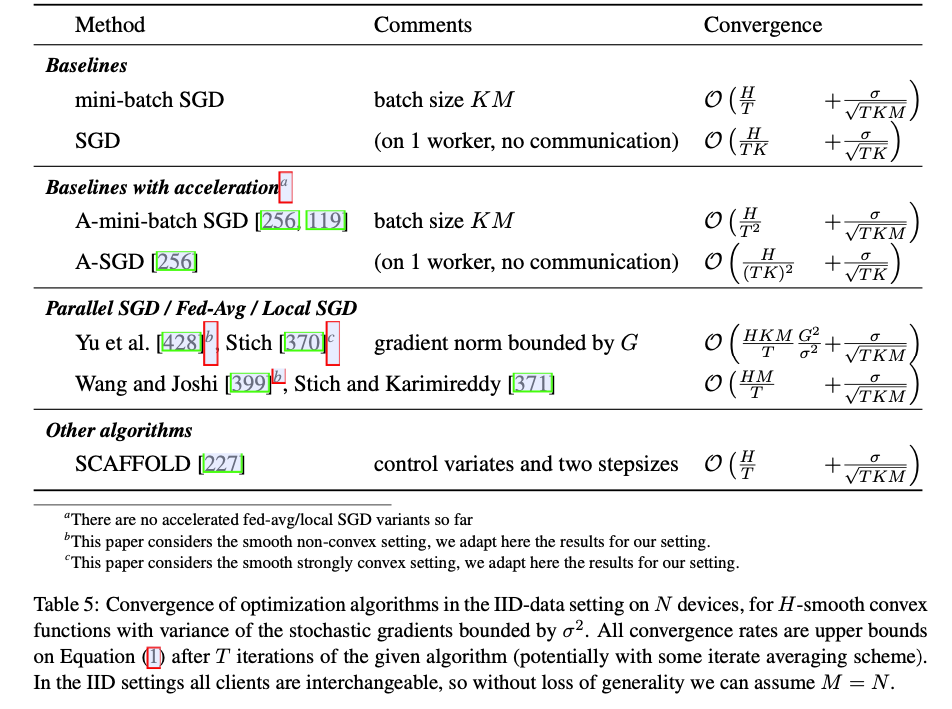
- 问题:
- 参数设计:时间开销(通信、本地计算)
- 参数设计:模型聚合方法(是否有利于收敛)
- 收敛速度能否达到mini-batch SGD?
- 参与者掉队问题的进一步分析
- 参与规模与设备差异的trade-off
Optimization Algorithms and Convergence Rates for Non-IID Datasets
现有的一些成果:

设备数据差异,即每次选择设备就是采样过程。
- 强凸函数有利于问题分析、限制梯度方差的边界
- Decentralized SGD 的应用
- Momentum 模型:动量算法?
- Variance-reduction
3.Multi-Task Learning,Personalization,and Meta-Learning
在部署阶段,为不同的用户部署不同的模型,这往往与Non-IID数据相关。
Personalization via Featurization
为不同的用户部署不同的模型参数(权重)。
-
通过增加用户和内容属性可以实现(增加训练集,覆盖更多的用户,但这不是个性定制模型)。
-
基于设备的个性化模型参数能够满足这个要求(结合用户输入习惯、聊天上下文、常用词等)。
这只是针对用户的输入,很少有其他数据可以包含这种特征。
-
研究结合环境信息进行不同任务的模型构建是一个开放问题。
Multi-Task Learning
- 大多数Multi-Task Learning考虑设备一直参与训练,这对跨数据孤岛的FL比较友好,对跨设备FL不友好。
- 设计新算法,重新考虑全局模型与每个用户模型的关系,开放问题。
Local Fine Tuning and Meta-Learning
-
Local Fine Tuning:
部署阶段,模型下发后,会在本地进行参数微调,主要就是利用本地数据再进行训练,然后投入预测使用。还有其他方式:迁移学习、领域自适应、与本地个人模型相结合。
这些技术主要应用在source-target领域,结构更加丰富的FL还不适用。 -
Meta-Learning:
model-agnostic meta-learning (MAML),可以作为探索模型适应任务的起点(只需要一些本地梯度)。
MAML&FL的问题:
- 有监督学习的MAML评估算法注重图像分类。
- 全局模型与个性化模型之间的准确率差距:个性化应该比FL更适用?!但尚未统一标准衡量个性化模型性能。
- 同结构同性能的模型,会因为训练方式不同导致个性化能力不同。
- Multi-task/LTL框架下的个性化和隐私。
- 无参的LTL算法能否用于FL?
When is a Global FL-trained Model Better?
取决于数据在参与者中的分布!!!
4.Adapting ML Workflows for Federated Learning
Hyperparameters Tuning
-
使用不同的超参在资源受限的移动设备进行训练显然是受限的。
-
HPO关注的是模型的准确率而不是通信计算效率。
-
可以考虑FL下的HPO的效能目标。
-
要易于调参:像中心化训练的学习率等、FL也可以探索。
Federated learning adds potentially more hyperparameters — separate tuning of the aggregation / global model update rule and local client optimizer, number of clients selected per round, number of local steps per round, configuration of update compression algorithms, and more. In addition to a higher-dimensional search space, federated learning often also requires longer wall-clock training times and limited compute resources.
Neural Architecture Design(Neuarl Architecture Search,NAS)
-
受限于预定义的网络模型,开发者在没接触训练数据之前选择的预定义模型可能不是最优的。
-
对于特殊数据集上的特殊任务,常见的三种NAS算法:
- Evolutionary Algorithms
- Reinforcement Learning
- Gradinet Desent:梯度反向传播、权值共享
-
Weight Agnostic Neural Networks:如果能用于FL,可以不需要协作训练。
Weight Agnostic Neural Networks其固定网络的参数,通过更新网络的结构来优化神经网络
Debugging and Interpretability for FL
- 在ML工作流程中,为了任务训练,经验丰富的建模者会审查数据(数据完整性、调试错误分类、处理异常值、手动标记)==》违背FL的隐私安全
- 对待去中心化数据,需要研究隐私保护技术解决上面的问题,这也是一个开放问题。
- 如何提高FL DP generative models的保真度。
5.Communication and Compression
- 无线连接、客户端网络速率慢。
- 模型更新稀疏化、量化能够大大较少通信开销,而且对准确率影响很小。
- 对通信速率的理论研究往往会忽略优化算法。(实际很难到达理论结果)
Compression objectives
| objectives | where | symbol |
|---|---|---|
| Gradient compression | clinets --> server | (a) |
| Model broadcast compression | server -->clients | (b) |
| Local computation reduction | local training procedure | © |
- (a)在执行过程中作用比较大
- 对(a)的研究较多、(b)的较少
- 跨设备FL不能假设设备保留了任何状态,但跨数据孤岛FL不同(同一设备可以重复参与计算),这种情况下可以解决(a),(b)。
- 对解决上述三个问题的同时生成紧凑模型的研究有很大的应用潜力。
- 研究数据相关压缩方案:对数据压缩和梯度压缩都有很大的提升。
Compatibility with differential privacy and secure aggregation
- 安全聚合&差分隐私与压缩&量化通信不可兼得。(前者均需要增加数据,与量化方法相违背)
- 安全聚合&差分隐私与压缩相结合是一个开放问题。
Wireless-FL co-design
无线干扰、噪声信道、信道波动会阻碍信息交换
-
传统解决方法:如知识蒸馏(FD)等。
节点之间传输模型输出参数(对数函数,应该是数据预处理结果)而不是模型参数(梯度和权值)。
-
新思想:利用无线信道作为数据聚合。
不同的节点发送不同的模拟波,在服务端进行叠加,权重是无线频道系数。聚合快,参与节点越多训练越快。优于传统的正交频分复用。
6.Application To More Types of ML Problems and Models
目前FL主要考虑了监督学习。对于其他ML(强化学习、半监督、无监督、激活学习、在线学习)是开放挑战。
本节引入贝叶斯方法,意图利用贝叶斯方法为经典联邦学习提供概念上的提升,有学者利用贝叶斯方法对Non-IID数据和跨平台的模型聚合。
- 大多数深度学习模型无法解释不确定性也无法对参数学习进行概率解释。
- 贝叶斯神经网路对过拟合有较好的健壮性、可以利用小型数据集学习。
- 结合贝叶斯方法,降低不确定性。未来数据增长,可以实现网络决策。
0x04 Preserving the Privacy of User Data
0x05 Robustness to Attacks and Failures
0x06 Ensuring Fairness and Addressing Sources of Bias
Note:
- MAML
- 本地差分隐私与差分隐私
- 贝叶斯卷积神经网络
- Split Learning 的工作模式,及Nopeek-SplitNN的技术
- 强化学习
- 动量模型
- Decentralized SGD
参考:
 wechat
wechat