
ClusterGAN: Latent Space Clustering in Generative Adversarial Networks
下载链接
0x00 Abstract
While one can potentially exploit the latent-space back-projection in GANs to cluster, we demonstrate that the cluster structure is not retained in the GAN latent space.
In this paper, we propose ClusterGAN as a new mechanism for clustering using GANs. By sampling latent variables from a mixture of one-hot encoded variables and continuous latent variables, coupled with an inverse network (which projects the data to the latent space) trained jointly with a clustering specific ...

Reinforcement Learning ZouWei(III)
参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
0x08 随机策略梯度
到目前为止,基于值的方法可以在获得最优值的同时获得对应的动作,以此作为最优策略!
随机策略主旨:πθ(a∣s)=p(a∣s,θ)\pi_{\theta}(a|s)=p(a|s,\theta)πθ(a∣s)=p(a∣s,θ)是输出动作的分布概率,并非准确的动作,基于采样数据更新,而且采样也伴随着随机过程!
所以从当前状态到下一状态存在两个随机过程:动作的选择,状态的转移~
但是存在动作连续(或者数目很大的情况),argmaxaQ(s,a)argmax_a Q(s,a)argmaxaQ(s,a)就变得不切实际,因此可以直接将策略参数化,利用线性或者非线性函数表示策略,即πθ(s)\pi_{\theta}(s)πθ(s),以寻求最优的参数θ\thetaθ,使得累计回报的期望E[∑tR(st)∣πθ]E[\sum_t R(s_t)|\pi_{\theta}]E[∑tR(st)∣πθ] 最大,这就是策略搜索方法。
最先发展的策略搜索方法是随机策略梯度,求解最优目标时,采用梯度 ...
Reinforcement Learning ZouWei(II)
参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
0x07 值函数逼近
存在状态连续(或数目很多)的情况,这是存储表格已经不现实了。 注意:此时只是说状态数目多,未提及动作!
所以在想能不能设置一个函数,根据输入状态返回值?通过训练这个函数的参数,实现更新表的功能。
因此引入值函数逼近:
V(s)=V^(s,θ)Q(s,a)=Q^(s,a,θ)V(s) = \hat{V}(s,\theta)\\
Q(s,a) = \hat{Q}(s,a,\theta)\\
V(s)=V^(s,θ)Q(s,a)=Q^(s,a,θ)
逼近又分为线性逼近和非线性逼近:
123456789函数逼近 |------线性逼近 | |---增量法逼近 | |---批量法逼近 | |------非线性逼近 |---DQN |---Double DQN |---Dueling DQN
线性逼近
线性逼近就是将值函数表示为状态或者状态函数的线性组合,如:
V^(s,θ)=θTx(s)=∑i=1dθixi(s)\hat{V}(\boldsymbol{s}, ...
Reinforcement Learning ZouWei(I)
参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
0x01 基础概念
什么是强化学习?
学习&规划
前者是指智能体未知环境模型,需要不断与环境进行交互,不断改进策略
后者是指已知大部分环境模型,智能体不再与环境进行交互,根据状态转移概率和回报,不断进改进策略
探索&利用:
探索未曾尝试的决策,主要体现在强化学习算法中的随机策略。
利用已收集的知识,主要体现在一些算法的贪心策略。
预测和控制
又叫评估与改善。
分别对应强化学习的打分阶段和策略改善阶段。
0x02 马尔可夫决策
马尔可夫性:下一时间步的状态s′s's′,仅与当前时间步的状态sss和所选动作aaa相关,与之前的状态、动作无关。
马尔可夫决策五元组:<S,A,R,P,γ><S,A,R,P,\gamma><S,A,R,P,γ>
贝尔曼方程:
状态值函数的数学表示如下,其中GtG_tGt是指到结尾的累计收益:
Vπ(s)=Eπ[Gt∣St=s]=Eπ[Rt+1+γRt+2+...∣St=s]V_{\pi} ...
Federated Evaluation of On-device Personalization
下载链接
0x00 Abstract
In this work, we describe methods to extend the federation framework to evaluate strategies for personalization of global models. We present tools to analyze the effects of personalization and evaluate conditions under which personalization yields desirable models.
0x01 Federated Personalization Evaluation

致LowBee的第二封信
负能量吐槽,满满负能量!
PFA: Privacy-preserving Federated Adaptation for Effective Model Personalization
下载链接
目的:推测出数据分布相接近的节点,进行聚类。利用该集群对已有的全局模型进行参数微调,实现联邦个性化。
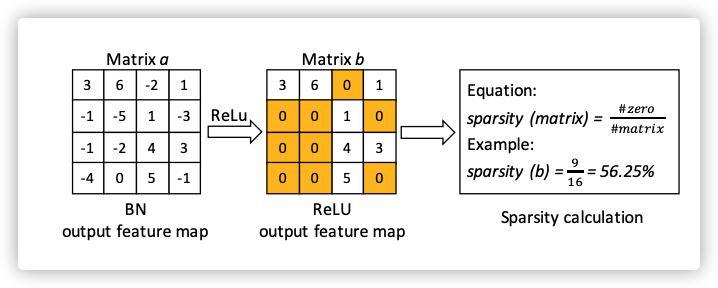
现在神经网络一般都会使用ReLU作为激活函数,这样处理后的矩阵就会是系数矩阵。
利用该矩阵的稀疏度表示这个原始数据(用处理后的数据表示原始数据,保证了数据的隐私安全)
多个样本稀疏度的均值,构成一个节点的稀疏度向量的一个元素。(向量的元素个数就是通道数)
计算两节点的相似性:
sim(Ri,Rj)=∑k=1q(Eik−Ejk)2sim(R_i,R_j)=\sqrt{\sum_{k=1}^q(E_i^k-E_j^k)^2}
sim(Ri,Rj)=k=1∑q(Eik−Ejk)2
其中:
q表示通道数
E表示稀疏度向量,长度为q
为防止计算相似度矩阵耗费O(N2)O(N^2)O(N2)的时间复杂度,本文计算相似度过程如下:
挑选一个节点zzz,计算其与其他节点的相似度向量:(sim(Rz,R1),sim(Rz,R2)...sim(Rz,Rn))(sim(R_z,R_1),sim(R_z,R_2)...sim(R_z,R_n))(sim(Rz ...

Commitment scheme
承诺机制入门
HFEL: Joint Edge Association and Resource Allocation for Cost-Efficient Hierarchical Federated Edge Learning
下载链接
Published in: IEEE Transactions on Wireless Communications
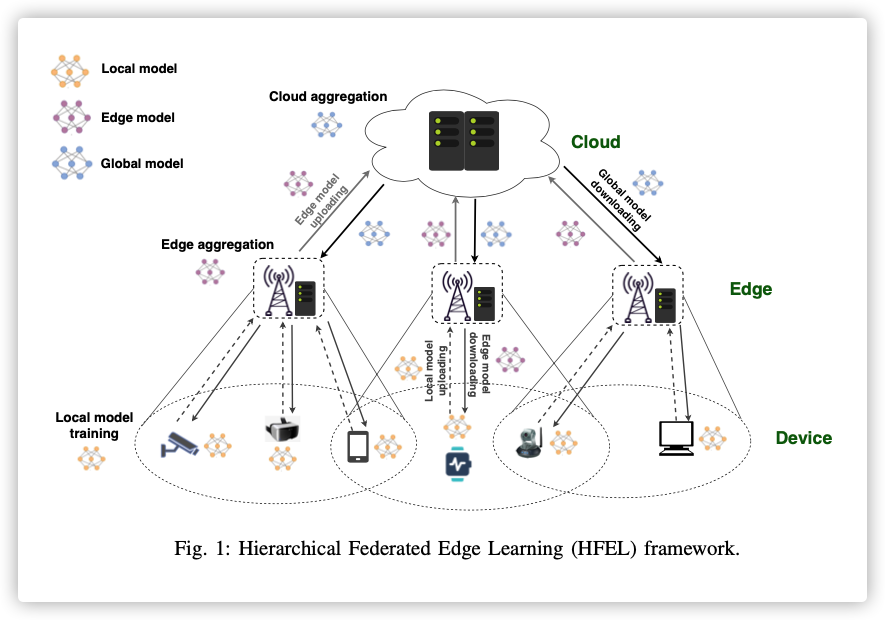
这篇论文是在多层联邦的情况下,讨论节点调度和资源分配的问题
0x00 Abstract
By leveraging edge servers as intermediaries to perform partial model aggregation in proximity and relieve core network transmission overhead, it enables great potentials in low-latency and energy-efficient FL. Hence we introduce a novel Hierarchical Federated Edge Learning (HFEL) framework in which model aggregation is partially migrated to edge servers from the cloud.
Key Words: Federate ...