DON’T USE LARGE MINI-BATCHES, USE LOCAL SGD
0x00 摘要
在相同效率和扩展性的情况下,提出Post-loacl SGD和Hierarchical Local SGD,能够提高泛化表现,优化系统资源。
KEY WORDS:Local SGD,Post-local SGD
0x01 介绍
为了有效利用系统资源,算法需要满足保证通信效率的同时启用并行化,且有良好的泛化性能。
Mini-batch SGD
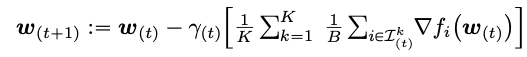
Local SGD
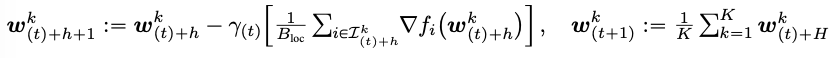
其中H表示本地训练步长,两者关系如下:
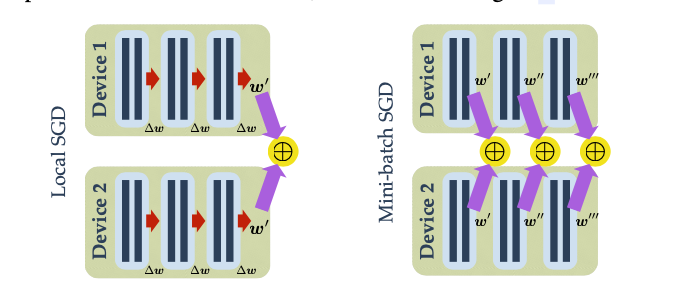
Large batch SGD
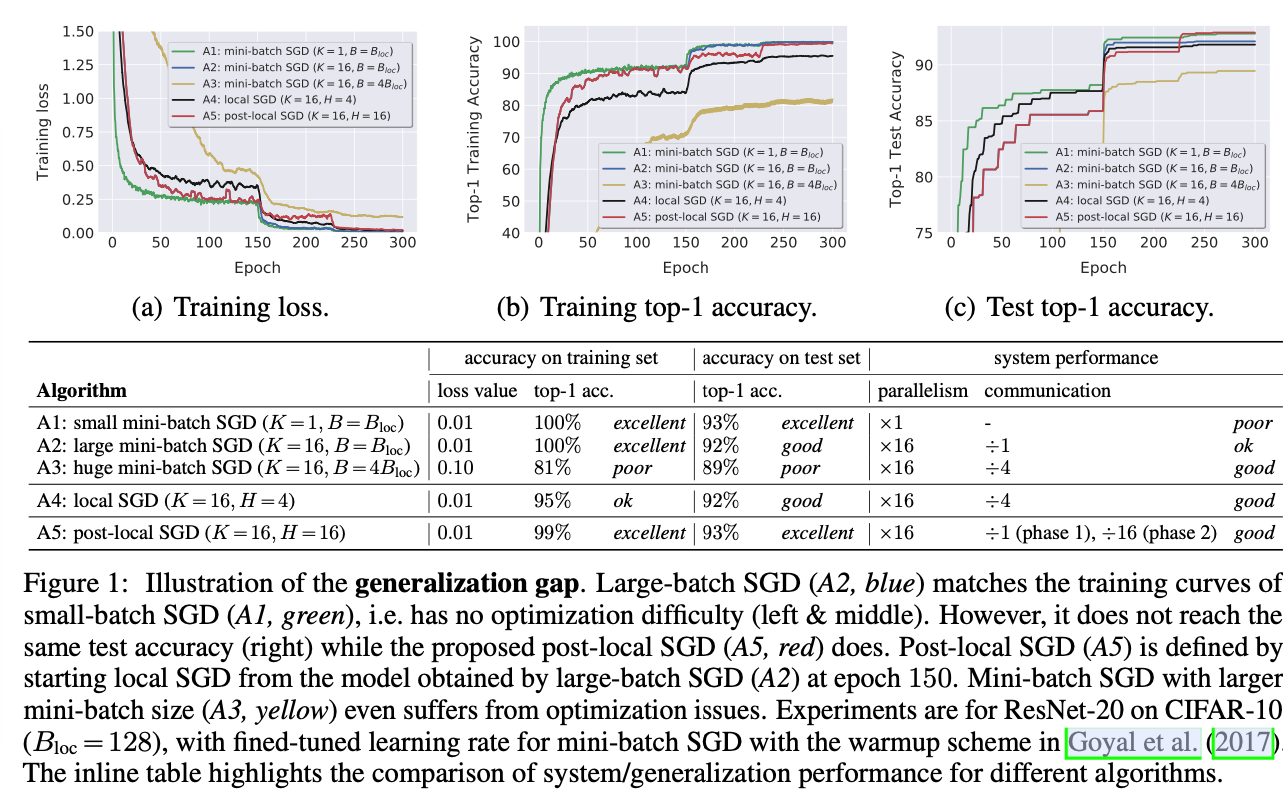
根据标准的mini-batch SGD扩大训练节点的数量,会使用更大的批次,这就导致系统效率和模型泛化能力下降,更会影响准确率。
以下两个场景除外:
- 通信限制设定:同步时间开销大于梯度计算时,可以使用大批次。
- 大批次泛化性能差:坚持使用小批次,保持并行性,会导致批次小于最优值,导致训练时间增加。
Main Results
Contributions
- 第一次全面的实践证明局部SGD通信效率和泛化性能的trade-off。
- 提出了Post-local SGD训练模式,提高了设备的并行性;在大批次训练情况下保证准确性。
0x02 相关工作
其他人做的事,有空再看。
0x03 梯度更新的变体
Post-local SGD:提高泛化准确率。
先进行若干次mini-batch SGD,再进行local SGD。
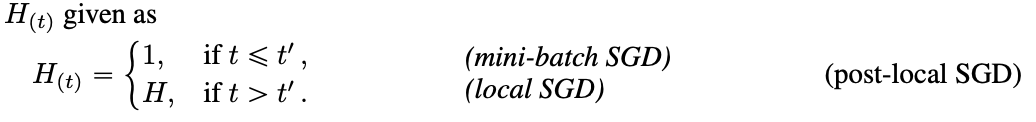
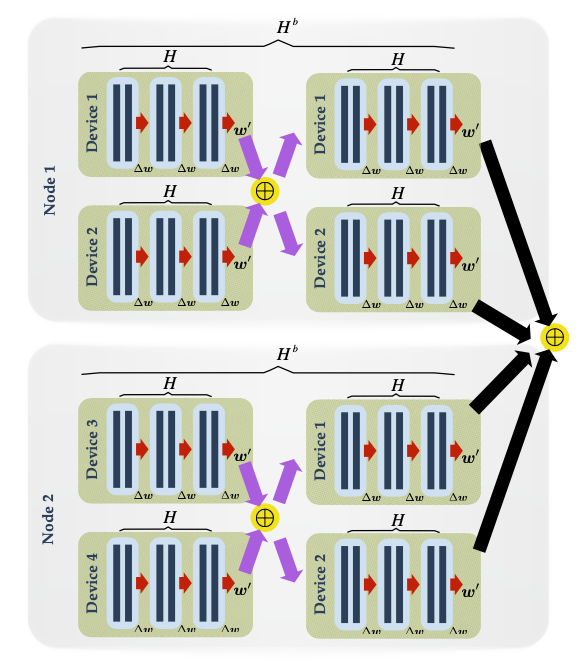
Hierarchical Local SGD:为了优化系统资源。
层次结构如下:
0x04 实验结果
更好的扩展性
- Significantly better scalability when increasing the number of workers on CIFAR, in terms of time-to-accuracy.
- Effectiveness and scalability of local SGD to even larger datasets (e.g., ImageNet) and larger clusters.
- Local SGD significantly outperforms mini-batch SGD at the same effective batch size and communication ratio.
解决Generalization Gap的问题
- Post-local SGD generalizes better and faster than mini-batch SGD.
- The effectiveness of post-local SGD training for different H and K.
- Post-local SGD can improve the training efficiency upon other compression techniques.
- Post-local SGD can improve upon other SOTA optimizers.
0x05 讨论&解释
-
泛化缺口问题
-
Post-local SGD收敛更平滑
0x06 总结
- 第一次研究local SGD的通信与效率的trade-off
- Post-local SGD 收敛更平滑,泛化效果更好
- Hierarchical local SGD更能有效利用系统资源。
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
 wechat
wechat
Related Articles

