Toward Knowledge as a Service Over Networks:A Deep Learning Model Communication Paradigm
DOI: 10.1109/JSAC.2019.2904360
0x00 总结
提出了一种基于多模型压缩的深度学习模型通信范例,极大地利用了不同应用场景下多个深度学习模型之间的冗余性。
KEY WORDS: Knowledge, KCN,Redundancy,DOM
0x01 介绍
**知识分布:**为了促进深度学习技术对知识的吸收与利用,知识分布能够缓和高昂的计算成本与设备能力有限之间的差距。
**通信问题:**使用知识分布后,许多应用对模型通信有较高的要求。(这也是深度学习的主要问题)
**冗余问题:**设备之间会分享相同的网络层或学习权重,这会影响通信效率。
主要工作总结:
- 提出并分析了重新构造KCN和人工智能环境下的知识交换的神经网络模型通信范例。
- 为了更好的编码效率,研究了基于消除模型间冗余的模型预测和压缩。
- 从各个角度验证了基于知识的深度学习模型通信性能,讨论并设想了深度模型压缩的未来标准化。
0x02 相关工作
- 重温现在常用的模型压缩方法,并说明与提出模型的关系。
- 提出一些可视数据的示例,进一步介绍KCN的知识交流的思想。
A 深度学习和网络压缩
基于深度学习的不同网络,都有了比较好的应用前景。但是对大量参数的计算和存储需要高额的开销。
常见的六种方式:
| 方法 | 介绍 |
|---|---|
| Parameters Pruning | 剪裁最不重要的参数 |
| Matrix Factorization | 低秩分解,使用矩阵对参数进行分解估计 |
| Filter Selection | 多层过滤器进行过滤 |
| Quantization | 权重量化就是较少表示每个权重所需要的比特数 |
| Knowledge Transfer | 知识蒸馏,将一个网络的知识转移到另一个网络 |
| Network Redesign | 基于轻量级网络结构和设计良好的模块重新设计 |
注:下发训练任务的通信开销,在文章[39]中提出的深度梯度压缩方式进行讨论和研究。(梯度)
本文:利用不同模型之间的冗余来降低深度模型传输开销。(模型)
B 知识中心网络 KCN
背景:受快速发展的深度学习和面向知识的网络范例启发,利用基于 知识创造、知识合成、知识部署的机器学习对传统CNN进行改进。
特点:对知识进行传输和使用,能够大大减少冗余,提高网络的智能。(传统网络上是使用原始数据)
示例:监控视频
-
与之相对的是传统内容中心网络:以原始数据为处理对象
-
用于提取特征信息;传输知识;
-
深度学习模型是一种特殊形式的知识、紧凑型深度学习模型的传输和标准化对促进知识交流具有积极作用。
说明深度学习在本文中的应用。
0x03 知识交流框架中的深度学习模型压缩
在知识交流框架中的模型压缩、边缘计算和云计算的应用场景。
A应用场景
1 基于云计算的知识交流
主旨:利用第三方算力存储和算力解决IoT设备算力不足的问题。
示例:智慧城市的视觉传感
问题:模型需要经常更新 ==》带宽和通信量 ==》需要模型压缩
2 基于边缘计算的知识交流
背景:IoT需要与云端有大量数据的上传与下载,带宽限制了云端服务器的性能。
主旨:利用云端与IoT之间的设备资源,提高靠近数据端的算力。从云端卸载计算,并在边缘缓存数据,能够大大改善用户体验。
示例:智慧城市的视觉传感,可以将产生的数据发送至边缘节点再进行处理。
- 云与边缘节点:本地训练模型、云端收集、将模型组合应用于其他场景。(类似Federated Learning)
- 边缘节点之间:为了特定任务,节点之间可以交换模型;甚至可以降低域内不同模块之间的冗余度。(信息共享)
B 关于KCN
- 目的:实现基于以知识为导向生成、组合和部署网络体系。
- 生成阶段:由于参数对数据和特定任务具有高度的代表性、知识范围扩展到模型。
- 组合阶段:不同的任务有不同模型组合;其中模型还包括预训练和半训练的模型(都经过了大量的样本训练、带有可用的知识),不仅仅是学习好的模型。
- 部署阶段:对网络压缩的研究依然很重要,模型压缩是知识部署高效的基础;制定比特流索引会提高协同工作的能力;需要对模型紧凑标准化进行研究(减少计算和内存占用方面)。
0x04 深度学习压缩与模型内部冗余删除
模型压缩还受到硬件资源的限制。任何深度学习的交流阶段都涉及到模型压缩。因此研究模型间的冗余可以促进深度学习模型的通信。
DoM计算方法:

A 单模型压缩
-
权值量化:对标量进行。
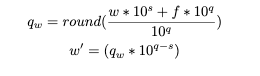
后续实验取
f=0.4。Question 1:为什么f能保证输入的权重和反量化的期望是一致的?
B 多模型冗余分析
在顺序模型传输下,用DoM表先前传输的模型与当前需要传输模型的差异。
当需要同时传输一组深度学习模型时,还应基于模型预测方法充分利用模型之间的冗余性。
从两个方面分析多模型预测的合理性:比较原始模型和DoMs的权重分布;利用K-L散度(相对熵)来衡量两个模型的概率分布偏离;
-
权重分布比较:(权值熵weight energy)
同种适用场景(VGG):由于模型间的预测,导致DoM权重分布更加集中。
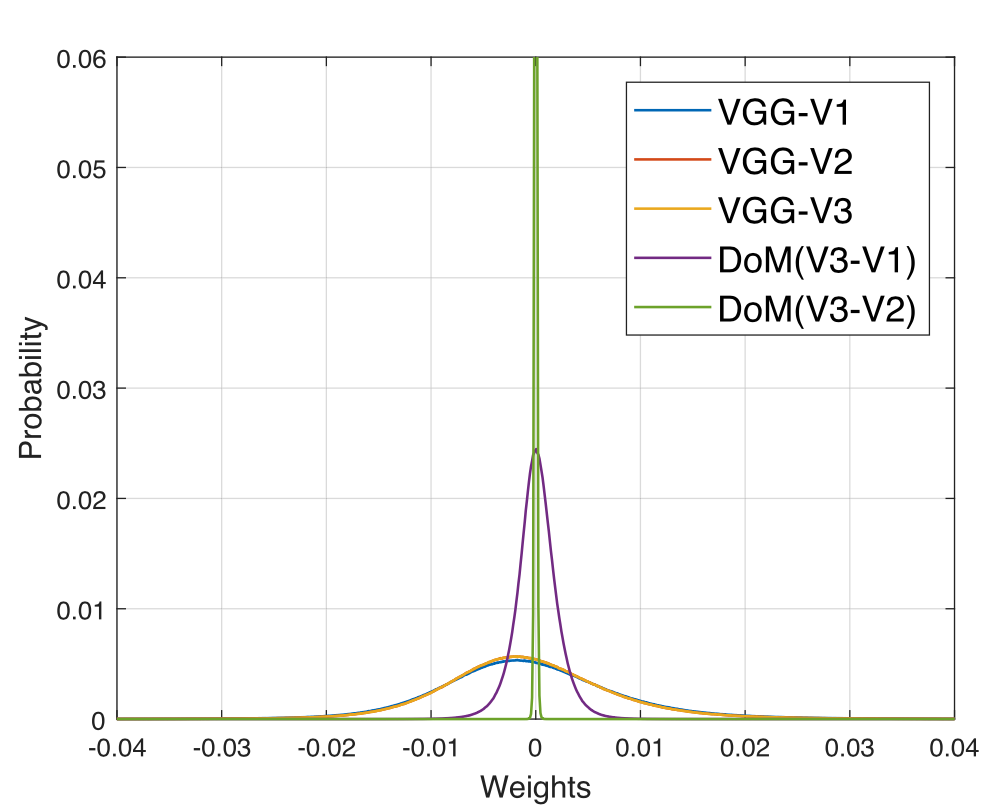
不同工作模型之间分析:依然能看见DoM的权值分布更加集中。
数学公式部分:拉普拉斯分布。
Question 2:为什么要采用拉普拉斯分布?
此处R是计算的信息熵。
-
相对熵分析:用于下面寻找最佳的Root模型。
研究不同模型之间的相对熵,相对熵越小说明两个分布越接近。
- 对于线性训练学习的模型,不同阶段的模型之间有大量的冗余。
- 同网络架构的不同训练任务,不同模型之间也会存在大量的冗余。
C 多模型压缩
基本原则:减少权重熵以求删除冗余。
选用模型分类:单模型随时间的顺序传输(对应前一阶段的VGG-V1,2,3),多模型的同时传输(能够同时获得不同模型)。
-
顺时传输模型方式:
-
云端和边缘节点能够不断接收新的数据、并用其对现有的模型进行训练;这种情况下、将模型传输后、存储端可以根据现有的模型预测当前需要压缩的模型;此时计算DoM 可以实现模型紧凑(DoM:预测模型与当前模型之间的参数微调等)。
-
提取DoM信息的方式是一层层的计算。很多时候,只有一小部分参数会得到更新时,只考虑更新部分权值。
-
需要考虑模型出错的问题:
1.量化导致的精度下降;
2.权重数目的减少和模型结构的改变导致模型减小;
-
-
并行模型压缩方式:
模型共享的学习模型要用相似的结构。==》找出Root模型。
过程:
- 所有的模型都是基于Root模型。(所有模型的相同部分)
- Root 模型采取单模型压缩方式。
- 接收端将DoMs 模型和Root模型重构原先的模型。
选择Root模型:K-L散度和共享内存。
D 关于标准化的讨论
未来可能有大量关于模型间冗余的研究,标准化很有意义。
标准化需要满足的属性:
- 确保深度学习模型通信的互用性;
- 减少模型的传输和存储;
- 为硬件支持的深度学习模型压缩提供标准格式;
- 实现符合标准的高水平执行能力;
- 为知识传输应用简化模型压缩设计。
0x05 验证工作
A 实验步骤
选取三个不同任务:分类、图像检索、目标检测。
B 模型顺序传输的实验结果
1 预测模型和待压缩模型均正确
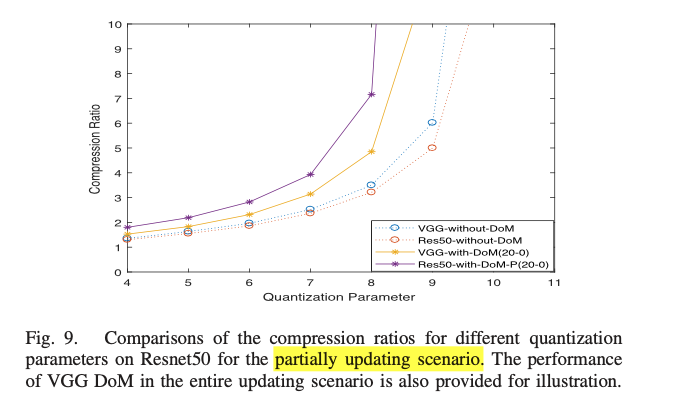
基本比较,都说明DoM能实现更好的模型压缩。
说明:表格5和图像7
注意图像7横坐标是Model Size,并非迭代次数,使用DoM的是指的DoM的大小。
没用DoM的模型是从中间开始的,使用DoM的应该是基于预训练的。
对比意义,在模型训练训练过程中,DoM会占用更少的带宽资源,并不是在一开始就使用DoM。(个人观点)
进一步比较,训练间隔变长,这就减少了模型之间的相似性。(对DoM模型是不利的)
表格6,DoM的压缩率仍比未使用DoM的高。

2 预测模型错误
数据集Cifar10/100
实验:量化参数的减少,表示模型不同程度的损坏。
结论:就算精度减少,不妨碍性能表现。

3 预测模型和待压缩模型均剪枝
实验结果表明模型间冗余删除,可以用于压缩后的模型。
C 模型同时传输的实验结果
不同工作的模型,一起传输。
在实验中,综合考虑K-L散度和共享内存后,classification模型被选做Root模型。
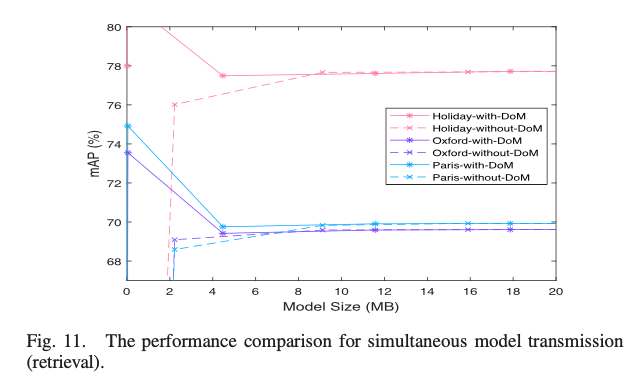
From Fig. 11, it is noticed that when the transmitted model sizes are among 4-6 MB, DoM strategy is able to maintain the performance while the performance begins to drop for the w/o-DoM strategy.
属实看不出来⊙﹏⊙|||
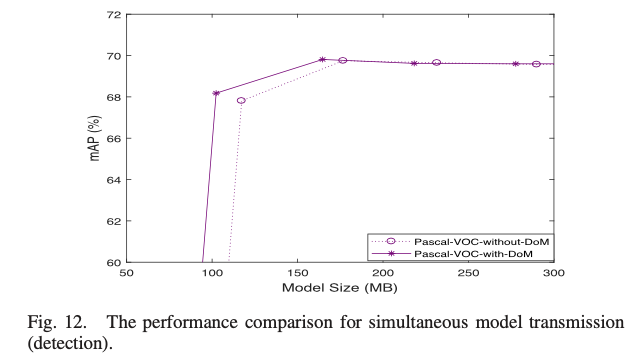
总结:在保证准确率的情况下,减少模型大小。
0x06 未来展望
模型间冗余还有发展前景,新压缩算法和标准会陆续发布。
两个问题:
- 如何选取最佳预测模型
- 如何制定模型压缩标准
参考:
 wechat
wechat

