参考书籍 邹伟博士的《强化学习》
此篇笔记用于整理知识,因此全部基于个人理解…
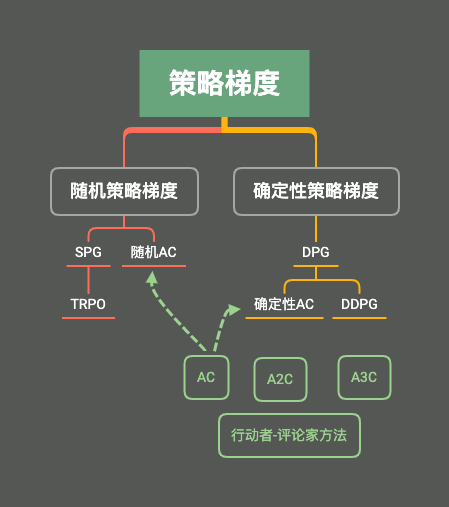
0x08 随机策略梯度
到目前为止,基于值的方法可以在获得最优值的同时获得对应的动作,以此作为最优策略!
随机策略主旨:πθ(a∣s)=p(a∣s,θ)是输出动作的分布概率,并非准确的动作,基于采样数据更新,而且采样也伴随着随机过程!
所以从当前状态到下一状态存在两个随机过程:动作的选择,状态的转移~
但是存在动作连续(或者数目很大的情况),argmaxaQ(s,a)就变得不切实际,因此可以直接将策略参数化,利用线性或者非线性函数表示策略,即πθ(s),以寻求最优的参数θ,使得累计回报的期望E[∑tR(st)∣πθ] 最大,这就是策略搜索方法。
最先发展的策略搜索方法是随机策略梯度,求解最优目标时,采用梯度上升法!(求解最大值)
优缺点及分类
- 更好的收敛性
- 更简单的搜索方法
- 可以学到随机策略
- 可能收敛到局部最小,学习不够高效!
随机策略梯度定理及证明
-
对于有终止状态的情况,可以使用累计回报作为目标函数,即:
J(θ)=Vπθ(s0)
-
对于没有终止状态的,考虑一段时间的回报期望作为目标函数,即:
J(θ)=t=1∑uπθ(s)a∑πθ(a∣s,θ)Rsa
其中uπθ(s) 是基于策略πθ生成的马尔可夫链关于状态的分布,在分布未知的情况下,就算目标函数对策略参数的梯度十分困难!
策略梯度定理能很好解决这种问题,并将上述两种情况在理论上统一成一种表示式:
∇J(θ)∝s∑uπθ(s)a∑Qπ(s,a)∇θπθ(a∣s,θ)=s∑uπθ(s)a∑πθ(a∣s,θ)Qπ(s,a)πθ(a∣s,θ)∇θπθ(a∣s,θ)=Es∼u,a∼π[Qπ(s,a)πθ(a∣s,θ)∇θπθ(a∣s,θ)]=Es∼u,a∼π[∇θlogπθ(a∣s,θ)Qπ(s,a)]
证明:
有时间再整理~
蒙特卡罗策略梯度
有上式知,需要根据采样at,st→a,s ,又因为Es∼u,a∼π[Gt∣st,at]=Qπ(st,at)所以有:
∇θJ(θ)=Es∼u,a∼π[∇θlogπθ(at∣st,θ)Qπ(st,at)]=Es∼u,a∼π[Gt∇θlogπθ(at∣st,θ)]
结合梯度上升公式θt+1=θt+α∇J(θt),则有REINFORCE方法:
θt+1=θt+αGt∇θlogπθ(at∣st,θ)
带基线的REINFORCE方法:
为了减少方差,因此引入基线函数b(s),其与动作无关,只与状态相关:
∇J(θ)∝s∑uπθ(s)a∑(Qπ(s,a)−b(s))∇θπθ(a∣s,θ)
而且不会改变梯度本身,其证明如下:
s∑uπθ(s)a∑b(s)∇θπθ(a∣s,θ)=s∑uπθ(s)b(s)a∑∇θπθ(a∣s,θ)=s∑uπθ(s)b(s)a∑∇θ1=0
TRPO方法
上述方法无法选择一个合适的步长α,使得学习方法单调收敛~
证明有些复杂~下次一定

0x09 Actor-Critic及变种
Actor-Critic 方法
Actor网络用于选择动作以达到最大的回报,Critic网络用于对动作进行打分,以减少回报估计值和回报真实之间的差距为目标。
训练时,两者同时训练,提升效果,只有好的评委才能指导出好的演员~
训练后,使用的就是Actor网络,根据状态选择动作
对行为值函数Qπ(s,a)进行参数近似:Qw(s,a),Actor按照Critic得到行为值函数,对参数θ进行更新:
Δθ=α∇θlogπθ(a∣s)Qw(s,a)
-
使用梯度上升更新Critic网络:
δ=r+γQw(s′,a′)−Qw(s,a)w=w+βδ∇wQw(s,a)
-
使用梯度下降更新Actor网络:
θ=θ+α∇θlogπθ(a∣s)Qw(s,a)



A2C (Advantage AC)方法
与前面介绍的REINFORCE方法一样,引入基线函数减少方差~
理论上基线函数满足只与状态相关即可,这里采用的基线函数B(s)=Vπθ(s)
则优势函数为:Aπθ(s,a)=Qπθ(s,a)−Vπθ(s)
目标函数的梯度如下:
∇θJ(θ)=Eπθ[∇θlogπθ(a∣s)(Qπθ(s,a)−Vπθ(s))]=Eπθ[∇θlogπθ(a∣s)Aπθ(s,a)]
如果根据上式进行更新,则Critic需要更新两套参数:更新V(s)一套, 更新Q(s,a)一套
但在实际操作中,要用TD误差代替优势函数进行计算,因为TD误差是优势函数的无偏估计:
δπθ=r+γVπθ(s′)−Vπθ(s)Eπθ[δπθ∣s,a]=Eπθ[r+γVπθ(s′)∣s,a]−Vπθ(s)=Qπθ(s,a)−Vπθ(s)=Aπθ(s,a)
因此只需要一套参数更新即可:
∇θJ(θ)=Eπθ[∇θlogπθ(a∣s)δπθ]
A3C
多个CPU线程进行异步学习,周期性同步参数~
0x0A 确定性策略梯度
对高纬度的行为空间的采样,和计算高纬度的期望非常复杂~
因此引入确定性策略:给定状态,返回一个动作~ a=μθ(s)
确定性策略梯度定理
假设在一个马尔可夫决策模型中,p(s′∣s,a),∇ap(s′∣s,a),μθ(s),∇θμθ(s),r(s,a),∇ar(s,a),p1(s)分别存在,并且对于s,s′,a,θ都是连续函数,(其中p1(s)表示初始状态概率分布函数,p(s′∣s,a)表示状态转移概率,以上条件时为了保证∇θμθ